안녕하세요, MiTornAve입니다.
지난 4회에서는 인공지능이 2차원 공간의 얽힘을 파악하고 시각적 추상화를 이루어낸 CNN(합성곱 신경망)의 눈을 가지게 된 과정을 살펴보았습니다. CNN은 이미지를 판독하는 데 압도적인 성능을 자랑하며 세상을 놀라게 했습니다.
하지만 세상의 모든 데이터가 한 장의 멈춰진 사진처럼 존재하는 것은 아닙니다. 빛이 있으면 시간이 흐르듯, 인공지능이 진정한 지능을 갖추기 위해서는 '시간의 축'을 이해해야만 했습니다. 가령, 이미지 한 장은 고양이과 강아지의 사진을 읽어서 사진에 있는 동물이 무엇인지를 알 수 있습니다.
하지만, 예를들어 자율주행 자동차의 제어시스템을 만들어 보자고 합시다. 자동차에 수 많은 센서를 달아두고, 출발 직전에 한 번의 데이터로 자율주행을 할 수 있을까요? 당연히 아닙니다. 즉, 동적인 시스템 내에서 계속되는 변화에 맞추어 인공신경망이 작동 하도록 '기억장치'가 필요하게 됩니다.
오늘 우리는 멈춰진 시야를 넘어, 어제의 기억을 오늘에 투영하는 인공지능의 기억 장치, RNN과 LSTM에 대해 파헤쳐 보겠습니다.
1. 멈춰진 사진에서 흐르는 시간으로: 시계열 데이터의 본질
주식 차트, 날씨의 변화, 심장 박동 그래프, 그리고 우리가 지금 나누고 있는 '문장'. 이들의 공통점은 무엇일까요? 바로 데이터의 '순서(Sequence)'가 결과에 결정적인 영향을 미친다는 것입니다.
"나는 오늘 점심으로 맛있는 [ ? ]"
이 빈칸에 들어갈 단어를 유추하려면, 그 이전에 등장한 '점심', '맛있는'이라는 단어들의 맥락을 기억하고 있어야 합니다. 앞서 배운 다층 퍼셉트론(MLP)이나 CNN은 과거의 데이터를 전혀 기억하지 못하는 금붕어와 같습니다. (남일 같지가 않다..)
이들은 수백 장의 사진을 1초 만에 판독하는 데는 천재적이지만, 소설책을 첫 페이지부터 차분히 읽어나가며 줄거리를 이해하는 데는 완전히 젬병입니다.
이 모델들은 매 순간 들어오는 데이터를 이전 상황과 완벽히 단절된, 하늘에서 뚝 떨어진 완전히 새로운 독립적 사건으로 취급해 버립니다. 어제 비가 오고 오늘 먹구름이 잔뜩 끼었다는 사실을 까맣게 잊은 채, 당장 지금 눈앞의 온도계 숫자만 보고 내일의 날씨를 맞추라는 격이죠.
과거를 잊은 모델에게 미래를 예측하라는 것은 그야말로 어불성설이었습니다. 인공지능이 눈앞의 멈춰진 찰나를 넘어 '진짜 지능'에 다가서기 위해서는, 어제의 일을 오늘로 이어가는 '기억'이라는 연속성을 반드시 획득해야만 했습니다.
2. RNN(순환 신경망): 과거를 현재에 투영하는 수학적 고리
과거의 정보를 기억하기 위해 과학자들은 신경망 내부에 아주 직관적이면서도 파격적인 구조를 도입했습니다. 정보가 입력에서 출력으로 한 방향으로만 직진하던 기존의 '피드 포워드(Feed-forward)' 구조를 비틀어, 출력의 일부가 다시 입력으로 돌아오는 '순환하는 고리'를 만든 것입니다. 이것이 바로 RNN(Recurrent Neural Network)의 탄생입니다.
2.1 은닉 상태(Hidden State): 신경망이 갖게 된 '단기 기억'
RNN의 가장 위대한 발명은 바로 은닉 상태(H_t)입니다. 이는 신경망 내부에 흐르는 '기억의 저장소'와 같습니다.
기억의 중첩: RNN은 현재 시점(t)에 들어온 입력값(X_t)만 보고 판단하지 않습니다. 바로 직전 시점(t-1)에서 계산되어 넘어온 '과거의 요약본'인 H_{t-1}을 함께 버무려 현재의 상태를 결정합니다.
재귀적 구조: 이 과정은 마치 우리가 소설을 읽을 때, 지금 읽고 있는 단어의 의미를 파악하기 위해 바로 앞 문맥을 머릿속에 남겨두는 것과 정확히 일치합니다. 층을 쌓는 것이 아니라, '시간을 쌓는' 방식이죠.
2.2 수식의 해부: 어제의 나와 오늘의 자극
RNN의 동작을 결정짓는 핵심 수식은 단순하지만 강력한 철학을 담고 있습니다.
H_t = \tanh(W_{hh}H_{t-1} + W_{xh}X_t + b)
두 세계의 만남: 수식을 보면 과거(H_{t-1})와 현재(X_t)가 각각의 가중치(W)라는 필터를 거쳐 하나의 벡터로 합쳐집니다.
가중치의 고정: 여기서 핵심은 시간이 흘러도 W_{hh}와 W_{xh} 값은 변하지 않는다는 점입니다. 즉, 어떤 시점에서든 동일한 '규칙'으로 과거와 현재를 결합합니다.
내일로 가는 징검다리: 이렇게 계산된 H_t는 현재의 출력값이 되기도 하지만, 동시에 다음 시점(t+1)의 입력으로 전달됩니다. "어제의 나(H_{t-1})와 오늘의 자극(X_t)이 만나, 내일로 전달될 새로운 나(H_t)를 형성한다"는 말은 단순한 비유가 아닌 수식 그 자체의 정의입니다. (현실에서는 '내일의 나'에게 모든 것을 넘기곤 한다.)
2.3 펼쳐진 시간(Unrolling): 루프 뒤에 숨겨진 거대한 신경망
겉보기엔 뉴런 하나가 뱅글뱅글 도는 것처럼 보이지만, 이를 시간 순서대로 펼쳐보면(Unrolling) RNN의 진짜 위력이 드러납니다.
입력이 5번 들어온다면, 동일한 가중치를 공유하는 5개의 층이 가로로 길게 연결된 형태가 됩니다. 즉, RNN은 데이터의 길이에 따라 가변적으로 길어지는 '매우 깊은 신경망'이 되는 셈입니다. 이 덕분에 RNN은 아주 짧은 단어부터 긴 문장까지 유연하게 대응할 수 있는 능력을 얻게 되었습니다.
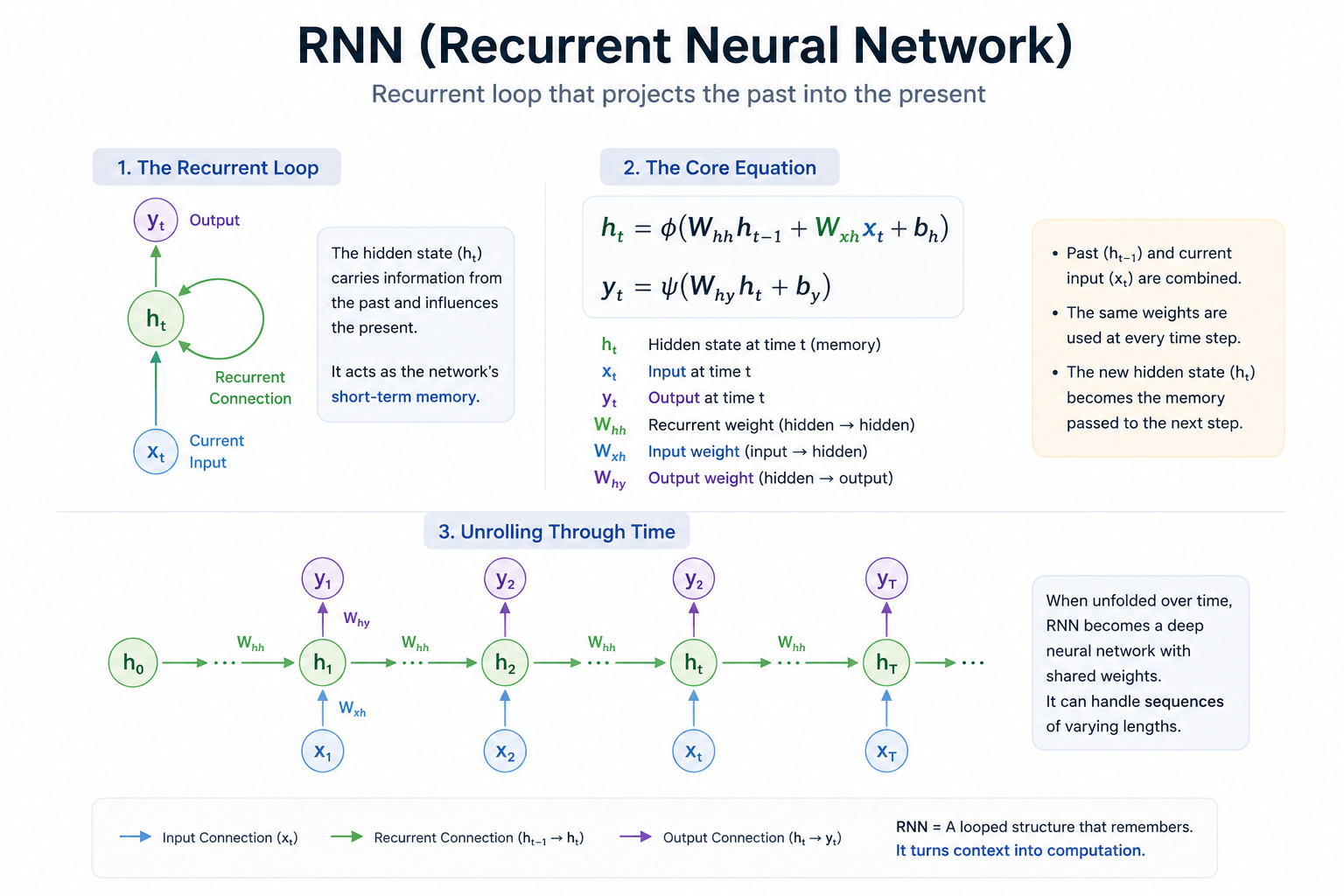
2.4 한 줄 요약: RNN의 본질
결국 RNN은 "맥락(Context)"을 숫자로 바꾼 모델입니다. 이전 단계에서 무엇을 보았느냐에 따라 똑같은 입력값도 전혀 다르게 해석할 수 있는 '지혜'를 갖게 된 것이죠. 하지만 이 아름다운 순환 구조에도, 시간이 너무 길어지면 과거를 잊어버리고 마는 '치명적인 약점'이 숨어 있었습니다.
3. 단기 기억 상실증: 장기 의존성(Long-Term Dependency) 문제
순환 신경망(RNN)이 가진 수학적 우아함 뒤에는 '장기 의존성(Long-Term Dependency)'이라는 아주 현실적이고 뼈아픈 한계가 기다리고 있었습니다. 이 문제를 이해하는 것은 왜 우리가 단순히 층을 쌓는 것을 넘어 LSTM 같은 복잡한 구조로 나아가야 했는지 알려주는 중요한 열쇠입니다.
아이러니하게도 RNN은 시간을 기억하기 위해 태어났지만, 역설적으로 치명적인 '건망증'을 앓고 있었습니다. 문장이 조금만 길어져도 문장 앞부분의 중요한 정보를 까맣게 잊어버리는 현상이죠.
3.1 "프랑스에서 왔는데 프랑스어를 못 한다고?"
우리가 자연스럽게 정답을 맞히는 아래의 예시를 모델에게 줘 봅시다.
"나는 프랑스에서 태어나 10년을 살았다. 그 후 한국으로 이주하여 학교를 다니고, 직장을 잡고, 어쩌고 저쩌고... 그래서 나는 [ ? ]를 유창하게 한다."
인간이라면 당연히 빈칸에 들어갈 말이 '프랑스어'라는 것을 직감합니다. 아주 먼 과거의 정보인 '프랑스'를 여전히 머릿속에 간직하고 있기 때문이죠. 하지만 순수한 RNN에게 이 문제는 난공불락의 성벽과 같습니다. 정보가 뒤로 전달될수록 초기에 입력된 '프랑스'라는 핵심 키워드는 점점 희석되어, 마지막 지점에 도달할 때쯤엔 그 형체조차 남지 않게 됩니다.
3.2 시간의 벽에 가로막힌 오차 신호: 기울기 소실
왜 이런 일이 벌어지는 걸까요? 그 범인은 바로 우리가 4화에서 다뤘던 기울기 소실(Vanishing Gradient) 문제입니다.
시간을 거슬러 올라가는 고통: RNN의 학습은 오차가 시간을 거슬러 올라가는 'BPTT(Backpropagation Through Time)' 방식을 사용합니다.
연쇄 법칙의 함정: 과거로 멀리 올라가려면 시그모이드(Sigmoid)나 탄젠트(Tanh) 같은 활성화 함수의 미분값을 계속해서 곱해야 합니다.
0으로의 수렴: 만약 이 미분값들이 1보다 작다면(보통 0.25 이하), 수십 번의 곱셈을 거치는 동안 오차 신호는 기하급수적으로 작아져 결국 0에 수렴하게 됩니다.
3.3 과거를 잊은 모델에게 내일은 없다
결국, 입력층에 가까운 아주 오래전 가중치들은 "어떻게 업데이트해야 할지" 알려주는 신호를 전혀 전달받지 못하게 됩니다.
오래전 정보가 소멸하니 모델은 바로 직전의 몇 단어에만 집착하게 되고, 문맥을 관통하는 거대한 흐름을 놓칩니다. 이름은 '순환 신경망'이지만 실제로는 '아주 짧은 단기 기억'만 겨우 유지하는 반쪽짜리 모델이 된 것이죠.
이 '심연에서 사라진 신호'를 구출하기 위해, 공학자들은 단순히 기억을 덮어쓰는 구조가 아닌, 중요한 정보만 골라 담는 특수한 장치를 고안하기 시작합니다. 그것이 바로 5회의 진정한 주인공, LSTM입니다.
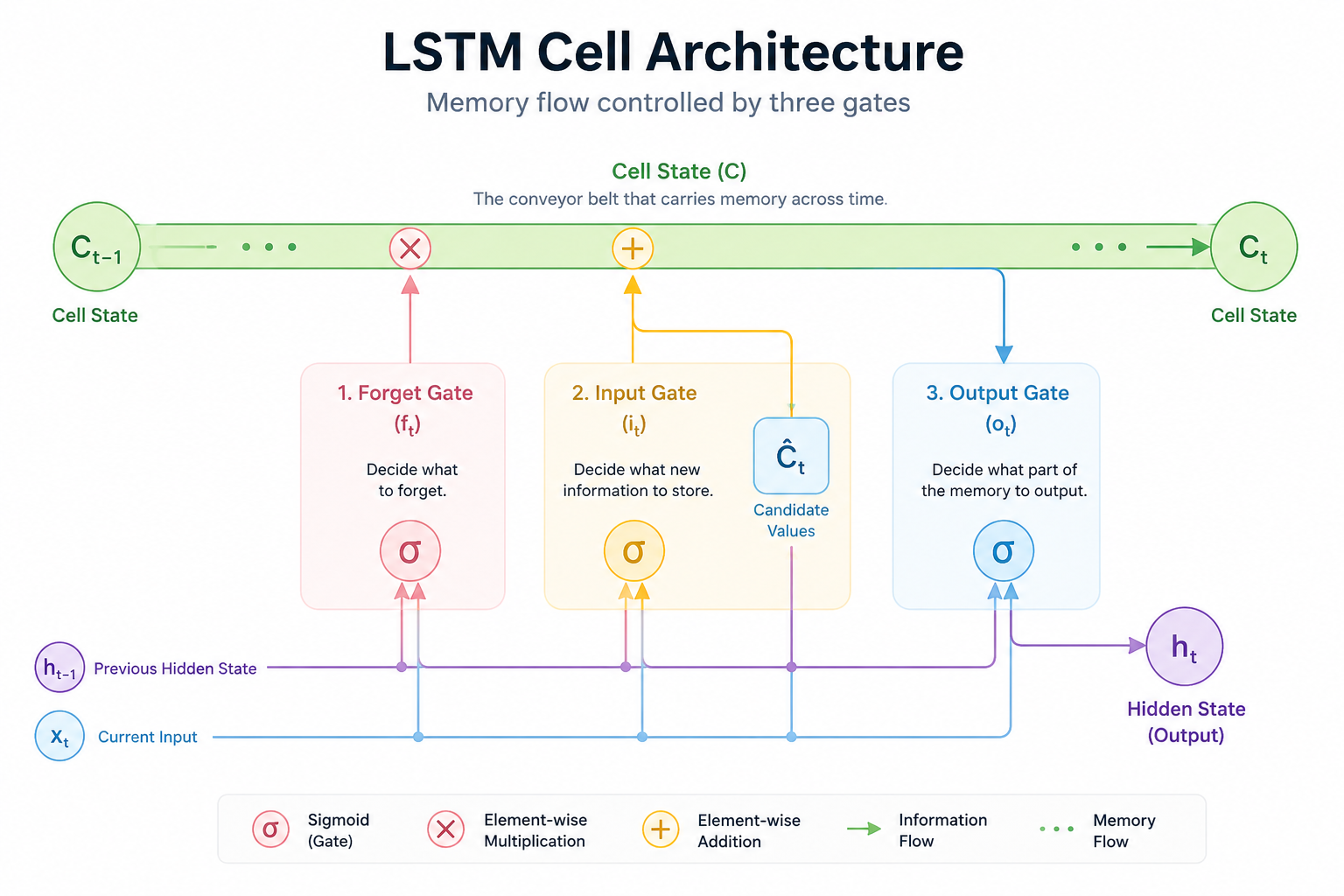
4. LSTM(장단기 메모리): 기억을 통제하는 컨베이어 벨트
1997년, RNN의 치명적인 건망증을 치료하기 위해 세프 호크라이터(Sepp Hochreiter) 등이 발표한 구조가 바로 LSTM(Long Short-Term Memory)입니다. 이름부터가 범상치 않죠? '긴 단기 기억', 즉 단기 기억을 아주 길게 가져가겠다는 의지가 담겨 있습니다. 이 구조는 발표 이후 수십 년간 현대 시계열 데이터 처리의 글로벌 표준으로 자리 잡았습니다.
LSTM의 천재성은 기억을 무작정 다음 단계로 우겨넣는 대신, 정보가 흐르는 '고속도로'를 뚫고 그 길목에 3개의 정교한 '밸브(Gate)'를 설치했다는 데 있습니다.
4.1 셀 상태(Cell State): 정보를 실어 나르는 메인 컨베이어 벨트
LSTM의 심장은 네트워크 전체를 가로질러 흐르는 셀 상태(C_t)입니다.
정보의 보존: 이는 공장의 메인 컨베이어 벨트와 같습니다. RNN처럼 매번 복잡한 연산을 거치며 변형되는 것이 아니라, 벨트 위에 정보를 올려두고 필요한 것만 살짝 더하거나 빼면서 끝까지 운반합니다.
장기 기억의 열쇠: 정보가 도중에 손실되지 않고 온전히 흐를 수 있는 통로가 확보되면서, 드디어 인공지능은 문장 맨 앞의 단어를 문장 끝까지 잊지 않고 가져갈 수 있는 '장기 기억력'을 얻게 되었습니다.
4.2 3개의 게이트(Gate): 기억을 관리하는 스마트 밸브
컨베이어 벨트 위로 흐르는 기억을 관리하기 위해 LSTM은 3가지 제어 장치를 둡니다. 이들은 문을 얼마나 열고 닫을지 0(완전 차단)에서 1(완전 통과) 사이의 값으로 결정합니다.
망각 게이트 (Forget Gate, f_t) - "버릴 것인가?"
과거의 기억 중 불필요해진 것을 '얼마나 지울지' 결정합니다.
예를 들어, 소설 속 주인공이 '남자'에서 '여자'로 바뀌었다면, 이전까지 유지하던 '남성형 대명사'에 대한 기억은 과감히 벨트 밖으로 던져버리는 식입니다.
입력 게이트 (Input Gate, i_t) - "새로 담을 것인가?"
현재 시점에 들어온 새로운 정보 중 '얼마나 저장할 가치가 있는지' 판단합니다.
중요한 핵심 키워드라면 벨트 위에 새로 올리고, 사소한 수식어라면 그냥 흘려보냅니다. 이 과정에서 선택된 정보가 장기 기억(셀 상태)에 최종 합류하게 됩니다.
출력 게이트 (Output Gate, o_t) - "무엇을 보여줄 것인가?"
정제된 장기 기억(C_t)을 바탕으로, 현재 시점에서 밖으로 내보낼 최종 결과물(H_t)을 산출합니다.
단순히 기억을 갖고만 있는 게 아니라, 현재 상황에 맞춰 가장 적절한 '답변'을 골라 내뱉는 필터 역할을 수행합니다.
4.3 요약: 왜 LSTM이 이겼는가?
RNN이 들어오는 정보를 닥치는 대로 기억하다가 과부하로 쓰러졌다면, LSTM은 "무엇을 잊고, 무엇을 담고, 무엇을 내보낼지"를 스스로 학습합니다. 덕분에 우리는 수천 단어 뒤의 맥락까지 파악하는 놀라운 번역기와 음성 비서들을 가질 수 있게 되었습니다.
[실습 섹션] 구글 코랩(Colab)에서 RNN의 기억력 확인하기
수학적인 원리를 코드로 직접 확인해 볼 시간입니다. 아래 코드는 파이토치(PyTorch)를 이용해 "hello"라는 단어의 흐름을 RNN이 어떻게 기억하며 처리하는지 보여주는 아주 간단한 실험입니다.
빈 셀에 복사해서 실행(Shift + Enter)해 보세요.
Python
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
# 1. Data Preparation
# Goal: Predict the next character ('h' -> 'e', 'e' -> 'l', 'l' -> 'l', 'l' -> 'o')
char_set = ['h', 'e', 'l', 'o']
input_size = len(char_set) # 4 (One-hot size)
hidden_size = 8 # Dimensionality of memory
learning_rate = 0.1
# Mapping characters to indices and vice versa
char_to_idx = {c: i for i, c in enumerate(char_set)}
idx_to_char = {i: c for i, c in enumerate(char_set)}
# Input: 'hell', Target: 'ello'
x_data = [char_to_idx[c] for c in 'hell']
y_data = [char_to_idx[c] for c in 'ello']
# Convert to One-hot Encoding
# Shape: (Sequence_length, Batch_size, Input_size) -> (4, 1, 4)
x_one_hot = [np.eye(input_size)[x] for x in x_data]
X = torch.FloatTensor(x_one_hot).unsqueeze(1)
Y = torch.LongTensor(y_data)
# 2. Define Model
class SimpleRNN(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(SimpleRNN, self).__init__()
self.rnn = nn.RNN(input_dim, hidden_dim, batch_first=False)
self.fc = nn.Linear(hidden_dim, output_dim) # Decode memory to character prediction
def forward(self, x, hidden):
out, h_n = self.rnn(x, hidden)
# Reshape output to pass through Linear layer
# out shape: (Seq, Batch, Hidden) -> (4, 1, 8)
out = self.fc(out.view(-1, hidden_dim))
return out, h_n
model = SimpleRNN(input_size, hidden_size, input_size)
# 3. Loss & Optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# 4. Training Loop
print("--- Training Started ---")
for epoch in range(100):
model.train()
optimizer.zero_grad()
# Initialize hidden state (Batch_size=1, Layers=1, Hidden_dim=8)
hidden = torch.zeros(1, 1, hidden_size)
# Forward pass
outputs, _ = model(X, hidden)
# Calculate loss
loss = criterion(outputs, Y)
# Backward and optimize
loss.backward()
optimizer.step()
# Check intermediate results
if (epoch + 1) % 20 == 0:
result = outputs.data.numpy().argmax(axis=1)
result_str = ''.join([idx_to_char[c] for c in result])
print(f"Epoch [{epoch+1}/100], Loss: {loss.item():.4f}, Predict: {result_str}")
# 5. Final Result Check
print("\n--- Final Prediction Result ---")
model.eval()
with torch.no_grad():
hidden = torch.zeros(1, 1, hidden_size)
outputs, _ = model(X, hidden)
final_idx = outputs.data.numpy().argmax(axis=1)
final_str = ''.join([idx_to_char[c] for c in final_idx])
print(f"Input: 'hell' -> Predicted: '{final_str}'")
이 코드를 실행하면, 5번의 시간(Sequence)을 거치면서 데이터가 어떻게 처리되고, 마지막 순간에 앞선 정보들이 압축된 최종 '은닉 상태(Hidden State)'가 어떻게 구성되는지 확인할 수 있습니다.
파이썬 코드가 다소 복잡해 보일 수 있지만, 핵심은 "인공지능에게 'hell'이라는 글자를 보여주고 'ello'라고 대답하게 만드는 훈련"입니다. 각 단계별로 어떤 일이 벌어지는지 한 번 알아봅시다.
1. 무엇을 입력하고 무엇을 기대하나요? (Input & Target)
재료 (Vocabulary): 우리는
h, e, l, o라는 딱 4개의 글자만 사용합니다.입력값 (Input):
h -> e -> l -> l(hell)을 순서대로 하나씩 넣어줍니다.정답 (Target): 모델은
e -> l -> l -> o(ello)라고 대답해야 합니다.즉,
h를 보면e라고 답하고,e를 보면l이라고 답하는 법을 배우는 과정입니다.
2. 컴퓨터가 이해하는 방식으로 변환 (Encoding)
컴퓨터는 글자를 직접 읽지 못하므로 숫자로 바꿔야 합니다.
One-hot Encoding: 글자의 종류가 4개이므로, 각 글자를 4차원의 리스트로 만듭니다.
h=[1, 0, 0, 0]e=[0, 1, 0, 0]... 이런 식으로 '내 자리가 어디인지'만 1로 표시하는 방식입니다.
3. 모델의 구조 (SimpleRNN 클래스)
이 모델은 크게 두 부분으로 나뉩니다.
RNN 층: 들어온 글자를 보고 "지금까지 이런 글자들이 들어왔었지" 하며 기억(Hidden State)을 업데이트합니다.
Linear 층 (FC): RNN이 만든 '기억'을 바탕으로, "그래서 다음 글자는
e일 확률이 80%야"라고 최종 판단을 내립니다.
4. 사용법 및 학습 과정 (Training Loop)
코드를 실행하면 다음과 같은 순서로 학습이 진행됩니다.
기억 초기화: 처음에는 아무것도 본 게 없으니 기억(
hidden)을 0으로 채우고 시작합니다.예측: 모델에게 'hell'을 보여주고 대답을 듣습니다. 처음엔 아무 공부도 안 했으니 'hhhh'나 'oooo' 같은 엉뚱한 대답을 할 겁니다.
오차 계산 (Loss): 모델의 대답과 실제 정답('ello')이 얼마나 다른지 점수를 매깁니다.
수정 (Optimizer): 틀린 만큼 모델 안의 가중치(가중치라는 이름의 나사)를 조여서 다음번엔 더 잘 맞추게 합니다.
5. 결과 분석 (Result Analysis)
출력창(Console)을 보시면 이런 흐름을 볼 수 있습니다.
초기 (Epoch 20):
Predict: oooo(아직 감을 못 잡고 아무 글자나 내뱉음)중기 (Epoch 60):
Predict: eloo(어느 정도 맞추기 시작함)최종 (Epoch 100):
Predict: ello(완벽하게 순서를 이해함!)
[인터랙티브 시뮬레이션] 내 손으로 돌려보는 LSTM 기억 통제소
LSTM의 핵심인 '셀 상태(장기 기억)'가 망각 게이트와 입력 게이트에 의해 어떻게 업데이트되는지 직접 수치를 조절하며 확인해 보세요. 과거의 기억을 지우거나, 새로운 기억을 강하게 덮어씌우는 과정을 직관적으로 이해할 수 있습니다.
5. 정리하며: 시간을 정복한 인공지능
오늘 우리는 인공지능이 과거의 맥락을 이해하고 미래를 예측할 수 있게 만든 RNN과, 그 기억의 한계를 공학적으로 극복한 LSTM을 살펴보았습니다.
이 기술 덕분에 구글 번역기는 매끄러운 문장을 만들 수 있게 되었고, 애플 시리(Siri)는 여러분의 음성 파형을 인식할 수 있게 되었습니다. 하지만 AI의 진화는 여기서 멈추지 않습니다. 순차적으로 데이터를 읽어야만 하는 RNN 구조의 느린 속도를 부수고, 'Attention(주의 집중)'이라는 새로운 패러다임을 열어젖힌 괴물이 곧 등장하게 됩니다.