안녕하세요, MiTornAve입니다.
지난 2-2 에서는 시간의 흐름을 기억하며 문맥을 파악하는 RNN과 LSTM의 '기억력'에 대해 알아보았습니다. 인공지능이 과거의 정보를 잊지 않고 미래를 예측하는 과정은 마치 인간의 사고방식을 닮아 매우 흥미로웠죠.
하지만 실제 산업 현장이나 고도의 공학 설계 분야에서는 '정확한 기억'만큼이나 '압도적인 처리 속도'가 생명인 순간이 있습니다. 예를 들어, 수 밀리초(ms) 단위로 변하는 센서 데이터를 실시간으로 보정하거나, 복잡한 시스템의 출력값을 즉각적으로 예측해야 하는 상황 말입니다.
오늘 소개할 RBFNN(Radial Basis Function Neural Network, 방사형 기저 함수 신경망)은 바로 이런 '속도'와 '효율'의 정점에 서 있는 모델입니다. 딥러닝 논문을 읽다 보면 제어 시스템이나 수치 예측 분야에서 단골손님처럼 등장하는 이 모델의 정체를 함께 파헤쳐 보겠습니다.
1. 전역적 학습 vs 국소적 반응: RBFNN의 철학
우리가 흔히 아는 다층 퍼셉트론(MLP)은 모든 뉴런이 서로 연결되어 데이터가 들어올 때마다 신경망 전체의 가중치를 조금씩 수정합니다. 이를 '전역적 학습(Global Learning)'이라 합니다. 하지만 이는 데이터가 많아질수록 학습 속도가 느려진다는 단점이 존재합니다.
RBFNN(Radial Basis Function Neural Network)은 접근 방식부터가 다릅니다. 이 모델은 '국소적 반응(Local Response)'에 집중합니다. 그 구체적인 차이와 철학을 상세히 분석합니다.
1.1 전역적 학습 (MLP): "모두가 조금씩 변하는 거대한 시스템"
작동 원리: MLP에서 하나의 입력 데이터는 신경망 내 모든 층과 모든 가중치(W)에 영향을 미칩니다. 데이터 하나가 들어올 때마다 네트워크 전체가 들썩이며 반응하는 구조입니다.
비효율성: 모든 뉴런이 활성화되어 오차를 줄이기 위해 전체 가중치를 미세하게 조정해야 하므로, 데이터가 방대해질수록 연산량이 기하급수적으로 늘어납니다.
장기 기억의 함정: 새로운 데이터를 학습할 때 기존에 잘 다져놓은 가중치들이 전체적으로 틀어질 수 있습니다. 이로 인해 학습 속도가 정체되거나 이전에 배웠던 정보를 잃어버리는 현상이 발생하기 쉽습니다.
1.2 국소적 반응 (RBFNN): "필요한 곳만 깨어나는 효율적 시스템"
RBFNN은 입력 공간을 여러 개의 '영역'으로 나눈 뒤, 입력값이 속한 특정 영역만 담당하는 뉴런을 활성화합니다.
범위의 경제 (Radial Basis):
데이터 전체를 훑는 대신, 입력값이 특정 영역의 중심(Center)에 얼마나 가까운지를 측정합니다.
중심점(c_i)에서 멀어질수록 반응도가 급격히 떨어지며, 특정 반지름(Radial) 이내에 들어올 때만 의미 있는 출력을 내보냅니다. 즉, 관련 없는 데이터에는 아예 반응하지 않습니다.
레이더 시스템 (Local Approximation):
마치 지도 위에 여러 개의 레이더를 설치하고, 물체가 특정 레이더 가시거리 안에 들어왔을 때만 해당 레이더가 강하게 반응하는 것과 유사합니다.
각 은닉층 뉴런은 자신만의 '수비 범위'를 가집니다. 입력 데이터가 담당 구역이 아니라면 반응하지 않고, 구역 내에 들어온 데이터만 정밀하게 분석하여 처리합니다.
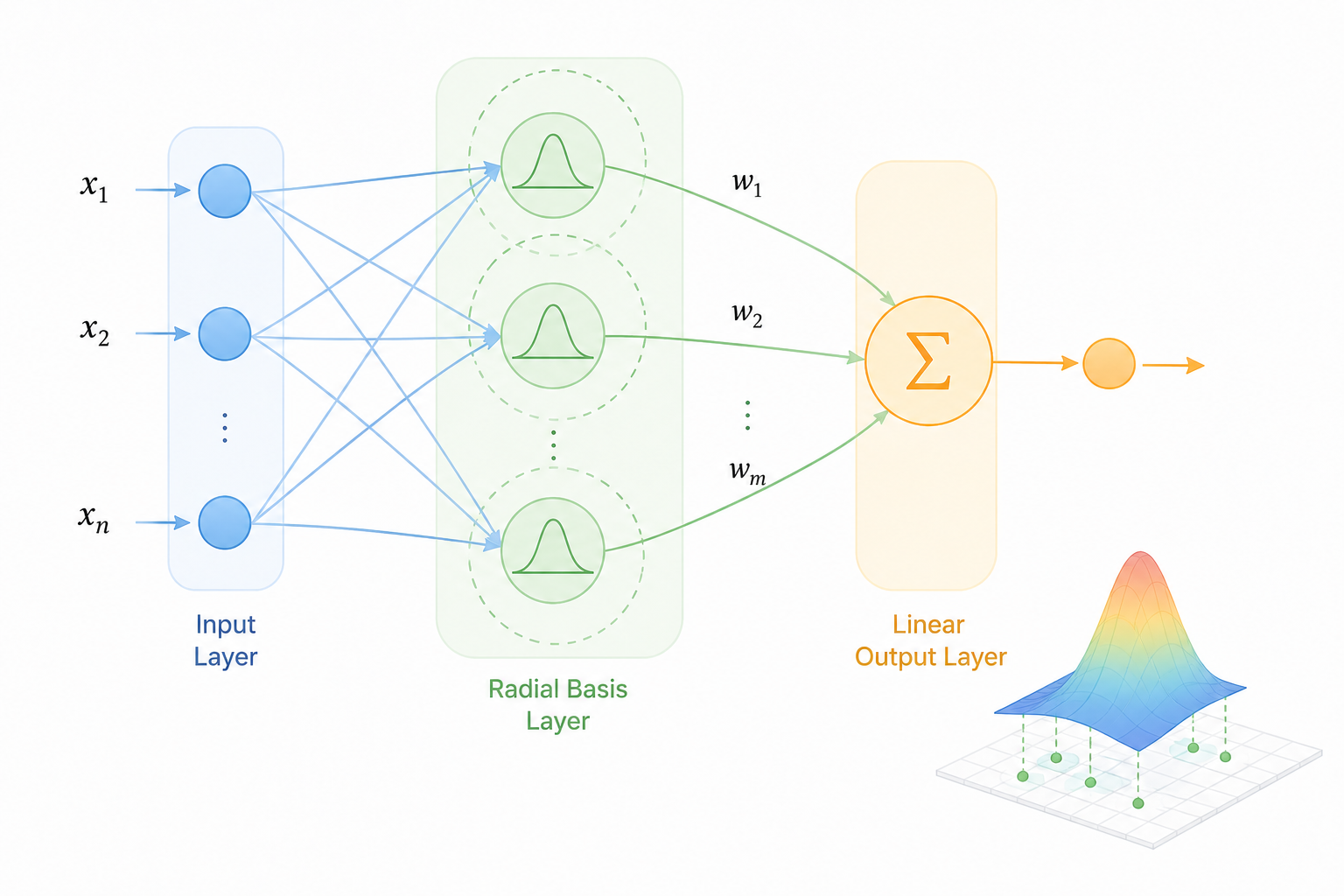
1.3 왜 RBFNN이 더 '초고속'인가?
이 '국소적 반응' 철학은 실제 학습 및 추론 속도에서 압도적인 차이를 만듭니다.
계산의 최적화: MLP처럼 수만 개의 가중치를 매번 동시다발적으로 업데이트할 필요가 없습니다. 현재 입력값 근처에 포진한 뉴런들만 계산에 참여하기 때문입니다.
독립적 학습: 각 뉴런이 특정 영역만 담당하므로, 한 구역의 학습이 다른 구역의 정보를 방해하지 않습니다. 덕분에 수렴 속도가 매우 빠릅니다.
수학적 간결함: 은닉층에서 가우시안 함수를 통해 거리를 계산하고 나면, 출력층에서는 단순히 가중치 합산(Linear Sum)만 수행하면 됩니다. 이 과정은 복잡한 반복 연산 없이 선형 대수학적 기법으로 최적의 해를 단번에 도출할 수 있습니다.
2. RBFNN의 구조: 단순함이 만드는 초고속의 미학
RBFNN은 복잡하게 여러 층을 쌓아 올리는 딥러닝 모델들과는 궤를 달리합니다. 단 세 개의 층으로 구성된 수평적인 구조를 통해 연산의 복잡도를 획기적으로 낮추면서도 강력한 근사 능력을 보여줍니다.
입력층 (Input Layer): 외부 데이터를 받아들이는 관문입니다. 별도의 연산 없이 입력된 수치들을 그대로 은닉층으로 전달하는 매개체 역할을 수행합니다.
은닉층 (Hidden Layer): RBFNN의 지능이 결정되는 핵심 구간입니다. 가중치 합을 구하는 일반적인 방식 대신, 각 뉴런이 가우시안 함수(Gaussian Function)를 사용하여 입력값과 자신의 중심점(Center) 사이의 거리를 계산합니다. 입력값이 중심에 가까울수록 출력값은 1에 수렴하며 강하게 반응합니다.
출력층 (Output Layer): 은닉층에서 계산된 국소적 반응값들에 가중치를 곱하여 최종 결과값을 도출합니다. 이 단계는 단순한 선형 합산(Linear Sum)으로 이루어지며, 비선형적인 데이터를 선형적인 문제로 치환하여 해결하는 마무리에 해당합니다.
2.1 왜 그렇게 빠른가? (학습의 분리)
RBFNN이 인공신경망 분야에서 '초고속 모델'로 불리는 이유는 학습 과정이 구조적으로 이원화되어 있기 때문입니다.
비지도 학습 단계 (은닉층): 먼저 데이터의 분포를 분석하여 은닉층 뉴런들이 담당할 중심점들을 배치합니다. 주로 FCM(Fuzzy C-Means)이나 K-Means 클러스터링 같은 기법을 사용하여 데이터의 '군집'을 먼저 찾아냅니다.
지도 학습 단계 (출력층): 중심점이 고정되면, 나머지 학습은 출력층의 가중치를 결정하는 것뿐입니다. 이는 딥러닝처럼 수만 번의 반복 계산(Iteration)이 필요한 역전파(Backpropagation) 과정 없이, 최소자승법(Least Squares Method) 등을 통해 수학적으로 최적의 해를 단 한 번에(One-shot) 계산해낼 수 있습니다.
2.2 RBFNN vs MLP: 구조적 차이가 만드는 성능의 향방
단순히 층의 개수뿐만 아니라 데이터를 바라보는 관점에서도 두 모델은 확연한 차이를 보입니다. 주요 차이점은 다음과 같습니다.
구조적 차이: 다층 퍼셉트론(MLP)은 여러 개의 은닉층을 수직으로 깊게 쌓아 올린 형태를 취하지만, RBF 신경망(RBFNN)은 단일 은닉층을 가진 넓고 수평적인 구조를 가집니다.
뉴런 작동 방식: MLP는 시그모이드(Sigmoid)와 같은 비선형 활성화 함수를 사용하여 데이터를 처리하는 반면, RBFNN은 거리 기반의 가우시안 함수를 사용하여 특정 중심점과의 거리를 측정합니다.
학습 범위: MLP는 데이터가 입력될 때 모든 뉴런이 동시에 학습에 참여하는 전역적(Global) 학습 방식을 따르지만, RBFNN은 입력값이 속한 특정 영역의 뉴런들만 집중적으로 반응하는 국소적(Local) 학습 방식을 사용합니다.
학습 속도: MLP는 오차 역전파(Backpropagation) 과정을 수없이 반복해야 하므로 학습 속도가 상대적으로 느립니다. 그러나 RBFNN은 학습 과정을 분리하고 출력층에서 단순 선형 연산을 수행하기 때문에 학습 속도가 매우 빠릅니다.
활용 분야: MLP는 이미지 인식이나 복잡한 패턴 분류와 같은 깊은 추론이 필요한 곳에 적합하며, RBFNN은 압도적인 속도가 필요한 실시간 제어, 시계열 데이터 예측, 그리고 정밀한 함수 근사에 주로 활용됩니다.
RBFNN은 입력 데이터가 자신이 담당하는 영역(Local)에 들어왔을 때만 예민하게 반응하므로 국소적인 데이터 변화에 매우 민감하게 대응할 수 있습니다. 이러한 특성 덕분에 데이터의 비선형성이 강하거나 빠른 응답 속도가 생명인 시스템 제어 분야에서 MLP보다 뛰어난 효율성을 자랑합니다.
3. 수식의 해부: 거리로 판단하는 지능
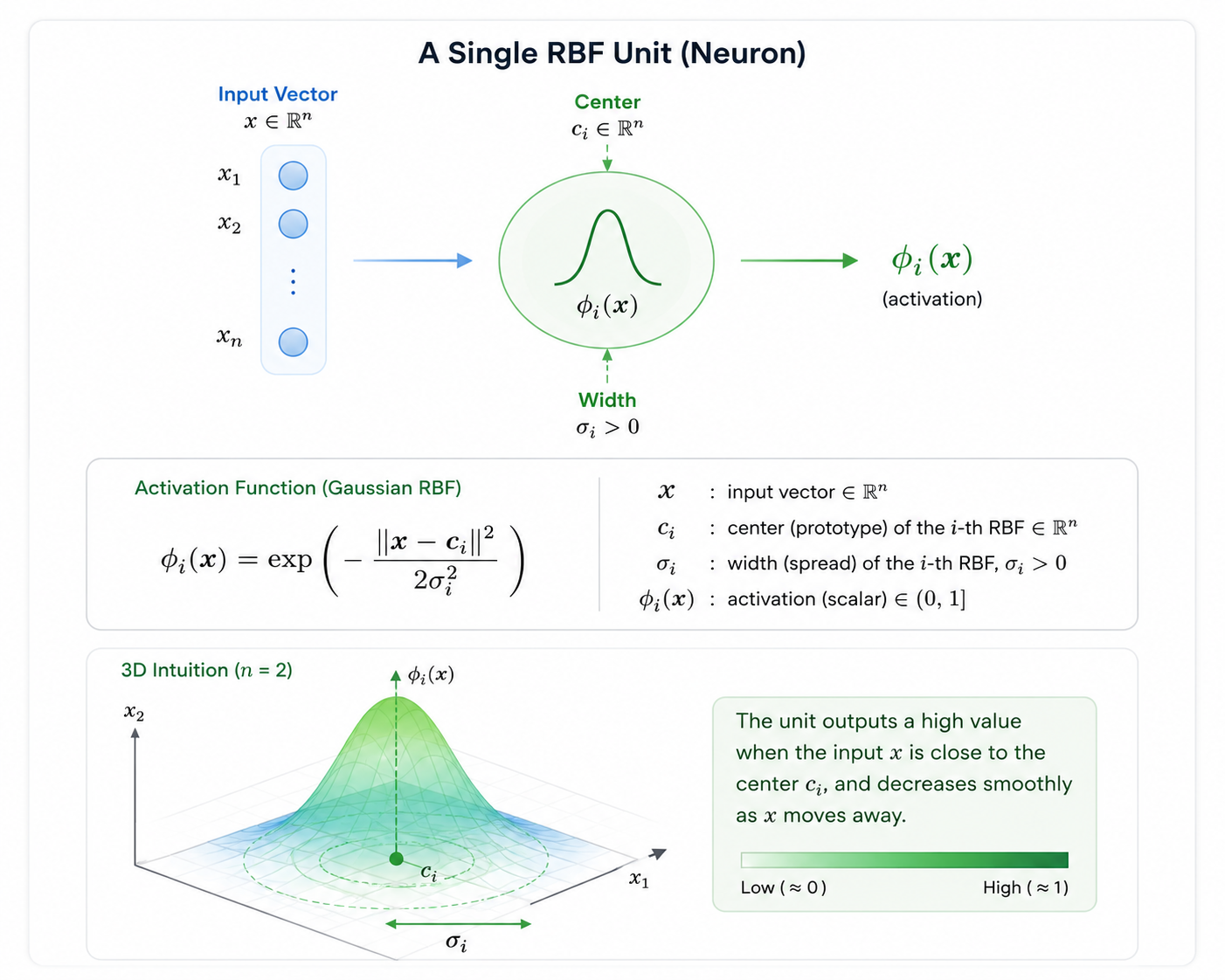
RBFNN의 은닉층에서 일어나는 마법은 다음 수식으로 요약됩니다.
\phi(x) = \exp\left(-\frac{\|x - c_i\|^2}{2\sigma_i^2}\right)
\|x - c_i\|: 입력값(x)과 중심점(c_i) 사이의 거리입니다. 거리가 가까울수록 결과값은 1에 가까워지고, 멀어질수록 0으로 수렴합니다.
\sigma (Sigma): 반응하는 범위의 폭입니다. 이 값이 크면 넓은 범위를 커버하고, 작으면 아주 좁은 영역에만 예민하게 반응합니다.
4. RBFNN vs MLP: 언제 무엇을 써야 할까?
논문을 작성하거나 프로젝트를 진행할 때 두 모델 사이에서 고민된다면, 각각의 특성에 따른 선택 기준을 고려해야 합니다. 단순히 층의 깊이뿐만 아니라 데이터를 해석하는 철학 자체가 다르기 때문입니다.
4.1 모델별 주요 특징 비교
학습 속도: 다층 퍼셉트론(MLP)은 오차 역전파(Backpropagation) 과정을 수없이 반복해야 하므로 학습 속도가 상대적으로 느립니다. 반면, RBF 신경망(RBFNN)은 학습 과정을 분리하고 출력층에서 단순 선형 연산을 수행하기 때문에 매우 빠른 학습 속도를 자랑합니다.
구조적 유연성: MLP는 여러 개의 은닉층을 수직으로 깊게 쌓아 올리는 다층 구조(Deep)가 가능합니다. RBFNN은 기본적으로 단일 은닉층을 가진 넓고 수평적인 구조를 취합니다.
데이터 근사 방식: MLP는 모든 뉴런이 동시에 학습에 참여하여 데이터 전체의 특징을 파악하는 전역적 근사(Global Approximation) 방식을 사용합니다. RBFNN은 입력값이 속한 특정 영역의 뉴런들만 집중적으로 반응하여 특정 영역에 특화되는 국소적 근사(Local Approximation) 방식에 집중합니다.
4.2 상황에 따른 선택 가이드
이미지 인식 및 복잡한 패턴 분류: 고차원 데이터에서 추상적인 특징을 추출하고 깊은 수준의 추론이 필요한 경우에는 MLP가 더 적합합니다.
실시간 시스템 제어: 초단위로 변하는 데이터를 즉각적으로 처리해야 하거나 연산 자원이 제한된 환경에서는 압도적인 속도를 가진 RBFNN이 유리합니다.
시계열 예측 및 함수 근사: 데이터의 비선형성이 강하거나 특정 수치 범위를 정밀하게 예측해야 하는 공학적 문제에서는 국소적 변화에 민감한 RBFNN이 뛰어난 효율성을 보여줍니다.
RBFNN은 입력 데이터가 자신이 담당하는 영역(Local)에 들어왔을 때만 예민하게 반응하므로 국소적인 데이터 변화에 매우 민감하게 대응할 수 있습니다. 이러한 특성 덕분에 빠른 응답 속도가 생명인 시스템 제어 분야에서 MLP보다 대체 불가능한 위치를 차지하고 있습니다.
[실습 섹션] RBFNN의 국소적 반응 확인하기 (Concept)
실제 RBFNN은 은닉층의 가우시안 커널이 어떻게 배치되느냐에 따라 성능이 결정됩니다. 아래는 간단한 개념적 흐름으로, 가우시안 RBF가 입력값에 따라 어떻게 반응하는지 볼 수 있습니다.
즉,
입력 xxx 가 중심(center)에 가까우면 → 강하게 활성화
멀어질수록 → 급격히 0에 가까워짐
이라는 RBFNN의 핵심 원리를 보여주는 코드입니다.
Python
# ============================================================
# Radial Basis Function Neural Network (RBFNN) - Basic Example
# Gaussian RBF Activation Visualization
# ============================================================
import numpy as np
import matplotlib.pyplot as plt
# ------------------------------------------------------------
# Gaussian Radial Basis Function
# φ(x) = exp( -||x - c||² / (2σ²) )
#
# x : input
# c : center of the neuron
# sigma : width (spread) of the Gaussian
# ------------------------------------------------------------
def gaussian_rbf(x, center, sigma):
distance_squared = np.linalg.norm(x - center) ** 2
return np.exp(-distance_squared / (2 * sigma ** 2))
# ------------------------------------------------------------
# Hyperparameters
# ------------------------------------------------------------
center = 0.0
sigma = 1.0
# Input range
x_values = np.linspace(-5, 5, 200)
# Compute RBF outputs
rbf_outputs = []
for x in x_values:
y = gaussian_rbf(x, center, sigma)
rbf_outputs.append(y)
rbf_outputs = np.array(rbf_outputs)
# ------------------------------------------------------------
# Print Example Outputs
# ------------------------------------------------------------
print("=== Gaussian RBF Outputs ===\n")
test_points = [0, 1, 2, 5]
for point in test_points:
output = gaussian_rbf(point, center, sigma)
print(f"Input x = {point}")
print(f"RBF Output = {output:.6f}")
if output > 0.7:
print("→ Strong activation (input is close to the center)\n")
elif output > 0.1:
print("→ Moderate activation\n")
else:
print("→ Very weak activation (far from the center)\n")
# ------------------------------------------------------------
# Visualization
# ------------------------------------------------------------
plt.figure(figsize=(10, 5))
plt.plot(
x_values,
rbf_outputs,
linewidth=3,
label='Gaussian RBF'
)
# Mark center point
plt.scatter(
[center],
[gaussian_rbf(center, center, sigma)],
s=100,
label='Center'
)
plt.title("Gaussian Radial Basis Function", fontsize=16)
plt.xlabel("Input x", fontsize=12)
plt.ylabel("Activation φ(x)", fontsize=12)
plt.grid(True, alpha=0.3)
plt.legend()
plt.show()위 결과처럼 거리에 따라 반응도가 급격히 변하는 특성이 RBFNN을 '경계에 강한 모델'로 만듭니다.이 코드를 돌리게 되면 아마 다음과 비슷한 결과를 얻으실 수 있습니다.
=== Gaussian RBF Outputs ===
Input x = 0
RBF Output = 1.000000
→ Strong activation
Input x = 1
RBF Output = 0.606531
→ Moderate activation
Input x = 5
RBF Output = 0.000004
→ Very weak activation이는, 중심인 0을 통과 하면 1이 바로 나타나고, 중심에서 멀어지는 값이 입력되면 점점 Output이 적어진다는 것을 보여줍니다. (아웃풋의 값은 각자 만들어진 RBFNN의 모뎅에 따라 상이해 질 수 있지만, 0일때 1일때 5일때를 비교했을 때 Output이 현저하게 낮아지는 것을 볼 수 있습니다.)
사실, RBFNN모델은 시계열 분석 등 범용이라기 보다는 공학 전반적인 부분에 걸쳐서 사용하기 때문에, 이 글을 보는 대부분은 공학도들일 경우가 많을겁니다. (아님 말구요) 따라서, 우리 공학도들의 자존심이자 쏘울인 MATLAB코드로 더 많이 접하게 될 거구요, 실제로 저도 이 코드를 베이스로 논문을 썼었으니까 여기에 MATLAB 버전을 하나 더 남겨두겠습니다.
% ============================================================
% Radial Basis Function Neural Network (RBFNN) Example
% Gaussian RBF Activation Function
% ============================================================
clc;
clear;
close all;
% ------------------------------------------------------------
% Parameters
% ------------------------------------------------------------
center = 0;
sigma = 1;
% Input range
x_values = linspace(-5, 5, 200);
% ------------------------------------------------------------
% Gaussian RBF Function
% φ(x) = exp(-(x-c)^2 / (2*sigma^2))
% ------------------------------------------------------------
rbf_outputs = exp(-((x_values - center).^2) ./ (2 * sigma^2));
% ------------------------------------------------------------
% Display Example Values
% ------------------------------------------------------------
fprintf('=== Gaussian RBF Outputs ===\n\n');
test_points = [0 1 2 5];
for i = 1:length(test_points)
x = test_points(i);
output = exp(-((x - center)^2) / (2 * sigma^2));
fprintf('Input x = %.1f\n', x);
fprintf('RBF Output = %.6f\n', output);
if output > 0.7
fprintf('-> Strong activation (close to center)\n\n');
elseif output > 0.1
fprintf('-> Moderate activation\n\n');
else
fprintf('-> Very weak activation (far from center)\n\n');
end
end
% ------------------------------------------------------------
% Visualization
% ------------------------------------------------------------
figure('Color', 'w');
plot(x_values, rbf_outputs, 'LineWidth', 3);
hold on;
scatter(center, 1, 100, 'filled');
title('Gaussian Radial Basis Function');
xlabel('Input x');
ylabel('\phi(x)');
grid on;5. 정리하며: 실전 공학의 강력한 도구
오늘 우리는 복잡한 시퀀스 대신, '거리'와 '범위'라는 직관적인 개념으로 초고속 연산을 수행하는 RBFNN에 대해 알아보았습니다. 비록 최근 딥러닝 트렌드가 아주 깊은 층(Deep Layer)을 선호하지만, 실시간성이 무엇보다 중요한 제어 및 예측 분야에서 RBFNN은 여전히 대체 불가능한 위치를 차지하고 있습니다.
이로써 우리는 시각(CNN), 기억(RNN/LSTM), 그리고 속도(RBFNN)라는 인공지능의 주요 무기들을 모두 살펴보았습니다.