안녕하세요, MiTornAve입니다.
지난 시간 우리는 '깊이'라는 속성이 인공지능에게 선사하는 추상화의 마법을 살펴보았습니다. 하지만 빛이 깊을수록 그림자도 짙은 법입니다. 층이 깊어질수록 오차의 신호가 심연 속으로 사라지는 기울기 소실과, 모델이 데이터의 잡음까지 외워버리는 과적합이라는 거대한 벽을 마주했죠.
시즌 1의 마지막 장인 오늘, 우리는 인류가 이 벽을 어떻게 허물고 '진정한 딥러닝'의 시대를 열었는지 그 최적화 기술들을 파헤쳐 보겠습니다. 이 기술들은 단순한 보조 장치가 아니라, 딥러닝이 이론을 넘어 실무에서 작동하게 만든 주인공들입니다.
1. 활성화 함수의 세대교체: ReLU의 혁명
기울기 소실 문제의 근본적인 원인은 역설적이게도 초기 딥러닝을 이끌었던 시그모이드(Sigmoid) 함수에 있었습니다.
시그모이드의 한계: 시그모이드는 함숫값이 0~1 사이로 제한되어 있어, 미분값이 최대 0.25에 불과합니다. 층을 하나 지날 때마다 신호가 최소 1/4 토막이 난다는 뜻입니다. 10층만 쌓아도 신호는 약 $100$만 분의 $1$로 줄어들어 사실상 소멸합니다.
ReLU(Rectified Linear Unit)의 등장: $f(x) = \max(0, x)$라는 지극히 단순한 이 함수는 현대 딥러닝의 구원자가 되었습니다.
신호의 무손실 전달: 양수 영역에서 미분값이 항상 1입니다. 층이 아무리 깊어져도 오차 신호가 약해지지 않고 입력층까지 '하이패스'로 전달됩니다.
희소성(Sparsity)의 미학: 음수 신호를 과감히 0으로 처리함으로써 중요한 특징에만 집중하게 만들고 연산 속도를 획기적으로 높였습니다.
2. 가중치 초기화(Weight Initialization): 시작이 성패를 결정한다
가중치(W)는 입력 신호가 다음 뉴런으로 전달될 때 그 세기를 결정하는 필터와 같습니다. 학습의 목적이 최적의 가중치를 찾는 것이라면, "어디서부터 찾기 시작할 것인가"는 학습의 속도와 성공 여부를 결정짓는 결정적인 요인이 됩니다.
2.1 0의 함정: 대칭성의 저주 (Symmetry Breaking)
처음 딥러닝을 접하면 "가장 중립적인 0이나 동일한 값으로 시작하면 공평하지 않을까?"라는 생각을 하기 쉽습니다. 하지만 이는 치명적인 결과를 초래합니다.
동일한 업데이트: 모든 가중치가 0(혹은 동일한 값)이면, 모든 뉴런이 동일한 출력값을 내뱉고, 역전파 시에도 동일한 오차 신호를 받게 됩니다.
학습의 무의미화: 결과적으로 수만 개의 뉴런이 있어도 모두 똑같이 움직이게 되어, 층을 여러 개 쌓은 효과가 완전히 사라지고 단 하나의 뉴런만 있는 것과 다를 바 없게 됩니다. 이를 방지하기 위해 우리는 반드시 가중치를 무작위(Random)로 설정하여 각 뉴런의 개성을 살려야 합니다.
2.2 분산의 마법: 신호의 생존과 폭주 사이의 균형
무작위로 정한다고 해서 아무 숫자나 넣어서도 안 됩니다. 여기서 공학자들은 '분산(Variance)'의 개념을 도입했습니다.
기울기 소멸 (Vanishing): 가중치 값이 너무 작으면 층을 거칠수록 신호가 급격히 작아져 결국 0이 되어버립니다. 신경망의 앞부분은 아무것도 배우지 못하게 됩니다.
기울기 폭주 (Exploding): 반대로 가중치가 너무 크면 신호가 기하급수적으로 커져 수치적 한계를 넘어서고(NaN 발생), 학습이 불가능해집니다.
2.3 Xavier 초기화 (Glorot Initialization)
2010년 자비에 글로로트(Xavier Glorot) 등이 제안한 이 방식은 시그모이드(Sigmoid)나 Tanh와 같은 S자형 활성화 함수를 사용할 때 가장 효과적입니다.
핵심 원리: 이전 층의 노드 수(n_{in})와 다음 층의 노드 수(n_{out})를 고려하여 가중치의 분산을 결정합니다.
수식의 의도: Var(W) = \frac{2}{n_{in} + n_{out}} 수준으로 설정하여, 입력 신호의 분산과 출력 신호의 분산이 일정하게 유지되도록 돕습니다. 덕분에 신호가 층을 통과해도 죽지 않고 끝까지 전달됩니다.
2.4 He 초기화: ReLU 시대의 표준
활성화 함수의 주류가 ReLU로 넘어가면서 Xavier 초기화에도 한계가 드러났습니다. ReLU는 입력의 절반(음수 영역)을 0으로 만들어 버리기 때문에 신호의 강도가 절반으로 줄어드는 특성이 있기 때문입니다. 2015년 카이밍 히(Kaiming He) 등은 이를 보정하는 새로운 공식을 내놓았습니다.
핵심 원리: ReLU 계열의 함수를 사용할 때는 Xavier 방식보다 분산을 2배 더 크게 가져가야 신호가 죽지 않습니다.
수식의 의도: Var(W) = \frac{2}{n_{in}} 정도로 설정합니다. 분산을 키워 ReLU에 의해 사라지는 신호의 양을 수학적으로 상쇄하는 것입니다.
현재의 위상: 현대의 거의 모든 심층 신경망(ResNet, VGG 등)은 기본적으로 ReLU를 사용하기 때문에, He 초기화는 사실상 업계 표준(Standard)으로 자리 잡았습니다.
3. 배치 정규화(Batch Normalization): 학습의 고속도로를 닦다
딥러닝 모델이 학습될 때, 앞쪽 층의 가중치가 변하면 그 결과물인 출력 데이터의 분포도 계속해서 변하게 됩니다. 뒤쪽 층들은 매번 변하는 입력 데이터의 분포에 적응해야 하는 고충을 겪는데, 이를 내부 공변량 변화(Internal Covariate Shift)라고 부릅니다. 2015년 등장한 배치 정규화는 이 문제를 정면으로 돌파했습니다.
3.1 강제적인 안정화: 데이터의 '표준화'
배치 정규화는 각 층에서 활성화 함수를 통과하기 전(또는 후), 미니배치(Mini-batch) 단위로 데이터의 분포를 강제로 조정합니다.
평균 0, 분산 1: 데이터를 평균이 0이고 분산이 1이 되도록 정규화하여, 모든 데이터가 일정한 범위 내에 머물게 만듭니다.
스케일링과 시프트: 단순히 0과 1로 고정하는 것이 아니라, 학습 가능한 파라미터($\gamma, \beta$)를 도입하여 신경망이 최적의 분포를 스스로 찾아갈 수 있는 유연함까지 갖췄습니다.
비유: 이는 마치 제각각인 크기의 돌들이 널린 비포장도로를 고른 두께의 아스팔트로 매끄럽게 닦아, 신호(데이터)가 저항 없이 빠르게 흐를 수 있게 만드는 것과 같습니다.

3.2 배치 정규화가 가져온 놀라운 부수 효과
이 기법은 단순히 분포를 맞추는 것 이상의 연쇄적인 이득을 제공하며 딥러닝의 패러다임을 바꿨습니다.
초기화의 굴레에서 해방: 앞서 언급한 가중치 초기화(Xavier, He)에 신경을 덜 써도 학습이 안정적으로 진행됩니다. 데이터 자체가 정규화되어 들어오기 때문에 초기값이 조금 빗나가도 금방 궤도에 오를 수 있습니다.
학습률(Learning Rate)의 극대화: 신호가 폭주하거나 소멸할 위험이 줄어들면서, 훨씬 공격적이고 높은 학습률을 설정할 수 있게 되었습니다. 이는 곧 학습 속도의 비약적인 상승(10배 이상)으로 이어집니다.
천연 규제제(Regularizer): 미니배치마다 평균과 분산을 계산하는 과정에서 발생하는 작은 노이즈가 의도치 않게 드롭아웃(Dropout)과 유사한 효과를 냅니다. 모델이 특정 데이터에 과도하게 집착하는 것을 막아 과적합 방지에도 기여합니다.
4. 과적합과의 전쟁: 정규화(Regularization) 기법
자, 우리가 지난 시간에 층을 엄청나게 깊게 쌓았잖아요? 그런데 문제가 생겼어요. 층이 너무 깊으니까 뒤쪽(결과값)에서 "너 틀렸어!"라고 소리를 질러도, 그 소리가 앞쪽(입력층)까지 가기 전에 다 쉬어버려서 안 들리는 거예요. 이게 바로 기울기 소실이었죠.
이걸 해결하려고 공학자들이 머리를 맞대고 찾아낸 '비장의 카드'들을 소개해 드릴게요.
4.1 가중치 초기화: "첫 단추만 잘 끼워도 절반은 간다"
처음에 가중치를 줄 때, 아무 생각 없이 다 0으로 주거나 똑같은 숫자를 주면 어떻게 될까요? 신경망에 있는 수만 개의 뉴런들이 다 똑같이 움직여요. 마치 축구 경기에서 11명 선수가 공 하나만 보고 다 같이 우르르 몰려다니는 꼴이죠.
Xavier & He 초기화: 이건 쉽게 말해서 "뉴런들한테 각자 자기 포지션을 잘 잡아주는 것"이에요. 너무 튀지도 않고, 너무 죽지도 않게 적당한 숫자를 골라주는 공식이죠.
Xavier는 옛날 방식(시그모이드)에 잘 맞고,
He는 요즘 대세인 ReLU랑 찰떡궁합이에요.
이렇게 시작점만 잘 잡아줘도 공부 속도가 말도 안 되게 빨라집니다.
4.2 배치 정규화: "공부하기 좋은 환경 만들기"
이게 진짜 대박이에요. 딥러닝 공부가 어려운 이유 중 하나가, 앞쪽 뉴런이 조금만 바뀌어도 뒤쪽 뉴런이 받는 데이터가 확확 변해버리거든요. 어제는 1~10 범위로 공부했는데, 오늘은 갑자기 100~1000이 들어오는 식이죠. 애가 정신을 못 차리겠죠?
배치 정규화: 그래서 각 층을 지날 때마다 데이터를 "야, 너네 너무 나대지 말고 딱 요만큼씩만 모여 있어" 하고 예쁘게 정리해 주는 거예요.
효과: 비포장도로를 아스팔트로 싹 깔아버리는 거랑 비슷해요. 길이 매끄러우니까 학습률을 높여서(속도를 높여서) 달려도 차가 안 뒤집어져요. 덕분에 예전보다 10배는 빨리 배울 수 있게 됐죠.
4.3 드롭아웃: "천재 한 명에게 의존하지 마라"
모델이 공부를 너무 열심히 하면 문제집 답안지를 통째로 외워버리는 과적합에 빠져요. 응용력이 제로가 되는 거죠.
드롭아웃: 이때 쓰는 방법이 참 재밌어요. 공부할 때마다 뉴런 몇 개를 무작위로 강제로 재워버리는 거예요.
왜 이럴까요? 특정 뉴런(에이스) 한 명한테만 의지하지 못하게 하려는 거예요. 에이스가 자고 있어도 나머지 뉴런들이 어떻게든 정답을 맞히려고 노력하다 보면, 전체적으로 아주 튼튼하고 응용력 좋은 모델이 완성됩니다.

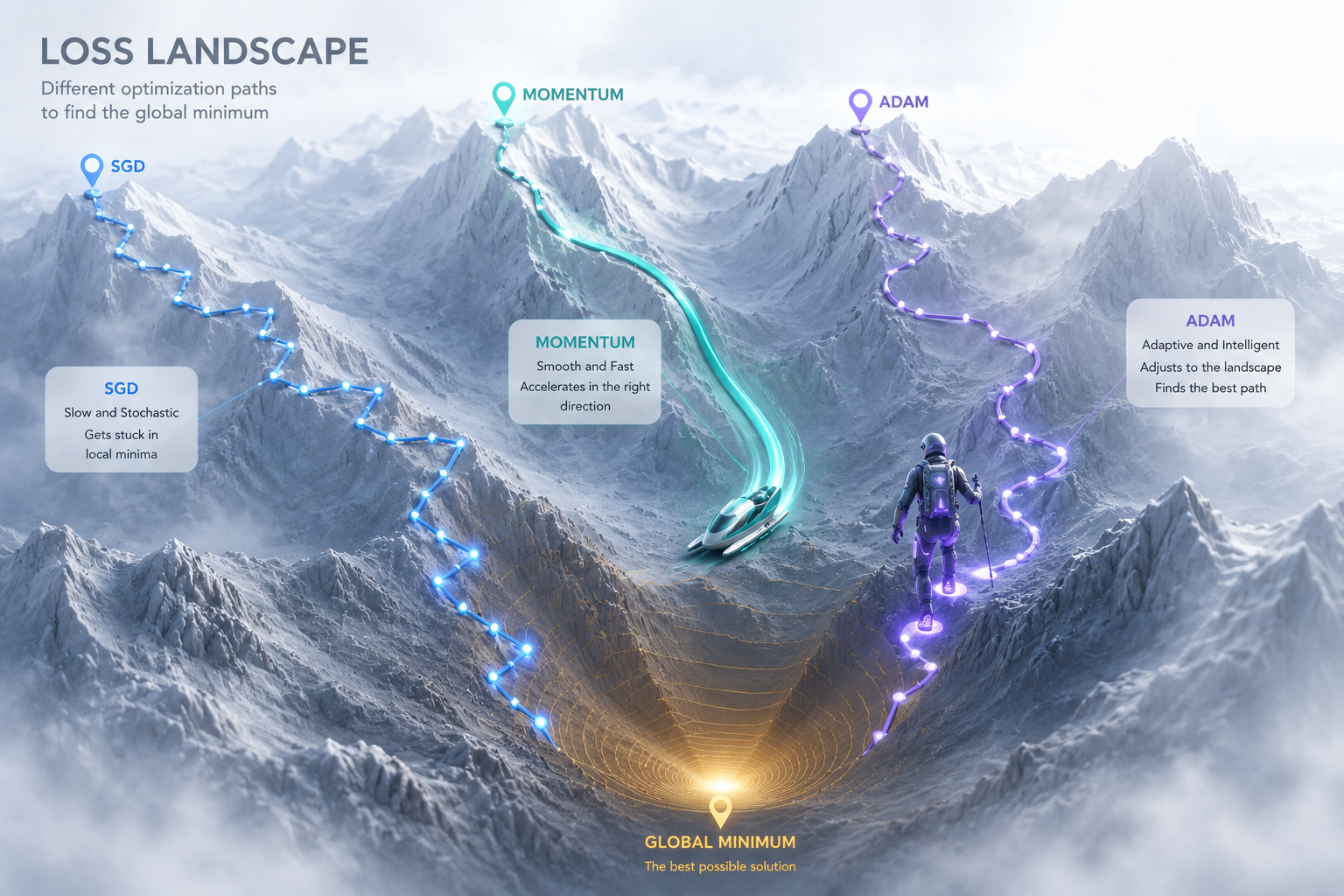
5. 경사하강법의 진화: 옵티마이저(Optimizer)
5.1 모멘텀(Momentum): "가던 속도를 활용하라"
우리가 눈 덮인 언덕에서 썰매를 타고 내려간다고 상상해 보세요. 썰매는 단순히 경사가 급한 곳으로만 움직이는 게 아니라, 내려오던 관성 덕분에 평지를 만나도 멈추지 않고 시원하게 미끄러져 나갑니다.
관성의 법칙: 이전에 이동했던 방향과 속도를 기억했다가 다음 걸음에도 반영합니다.
웅덩이 탈출: 덕분에 '지역 최솟값'이라는 작은 웅덩이에 빠져도 멈추지 않고 관성의 힘으로 슥 넘어갈 수 있습니다.
5.2 AdaGrad & RMSProp: "보폭을 유연하게 조절하라"
험한 산을 내려갈 때, 경사가 급한 곳에서는 조심조심 짧게 걷고, 완만한 곳에서는 성큼성큼 걷는 게 효율적이겠죠? 이 친구들은 변수마다 학습률(보폭)을 다르게 조절하는 '적응형' 길잡이입니다.
맞춤형 보폭: 그동안 많이 변했던(길이 잘 닦인) 변수는 보폭을 줄여서 정밀하게 살피고, 적게 변했던(아직 가보지 않은) 변수는 보폭을 넓혀서 빠르게 탐색합니다.
정밀한 착지: 목표 지점에 가까워질수록 보폭을 줄여주기 때문에, 정답을 지나치지 않고 우아하게 안착할 수 있게 도와줍니다.
5.3 아담(Adam): "최고의 장점만 모은 끝판왕"
요즘 딥러닝에서 "일단 이거 쓰세요"라고 말하는 가장 대중적인 도구입니다.
환상의 콤비: 위에서 말한 모멘텀(관성)의 시원함과 RMSProp(보폭 조절)의 섬세함을 하나로 합쳤습니다.
스마트한 탐험: 가던 방향으로 계속 가려는 힘은 유지하면서, 상황에 맞춰 보폭까지 조절하니 복잡한 오차의 산맥을 빠져나오기에 이보다 더 좋은 도구는 없겠죠?
시즌 1을 마치며: 우리가 쌓은 논리의 두께
드디어 시즌 1이 막을 내렸습니다. 우리는 단순한 퍼셉트론에서 시작해, 오차 역전파의 수학적 정수를 지나, 오늘 '깊이의 저주'를 극복하는 공학적 도구들까지 손에 넣었습니다.
이 기초 체력은 앞으로 우리가 마주할 거대한 AI 모델들—이미지를 보는 CNN, 언어를 이해하는 RNN과 Transformer—을 이해하는 유일한 열쇠가 될 것입니다. 딥러닝은 마술이 아니라, 수많은 천재들의 수학적 고민과 공학적 최적화가 빚어낸 결정체입니다.
다음 시즌에서는 이 튼튼한 뿌리 위에서 인공지능이 어떻게 세상을 보고(Computer Vision), 인간과 대화하는지(NLP) 본격적인 실전의 세계로 떠나보겠습니다. MiTornAve와 함께하는 인공지능 탐구, 시즌 2에서 뵙겠습니다!
핵심 키워드 복습
ReLU: 기울기 소실을 해결한 현대 딥러닝의 표준 활성화 함수.
He 초기화: ReLU 모델의 시작을 최적화하는 가중치 설정 기법.
배치 정규화: 학습 데이터를 안정화하여 속도와 안정성을 모두 잡는 고속도로.
드롭아웃: 뉴런을 무작정 끄는 방식으로 과적합을 방지하는 전략.