안녕하세요, MiTornAve입니다.
지난 시간 우리는 현대 인공지능의 심장인 '역전파'와 '경사하강법'을 통해 신경망이 어떻게 오차의 산맥을 내려오는지 살펴보았습니다. 하지만 단순히 내려가는 방법만 안다고 해서 모든 문제가 해결되는 것은 아닙니다. 마지막 경사하강법 파트에서 확인 하였듯이, 산맥이 너무나 거대하고 복잡하다면, 우리는 그 깊은 층(Layer)의 미로 속에서 길을 잃기 십상이기 때문입니다.
오늘 우리가 다룰 주제는 바로 그 유명한 딥러닝입니다. 지난 시간들로 여러분들은 딥러닝을 완전히 이해할 수 있는 배경지식을 가지게 되었습니다. 단순히 층을 많이 쌓는다는 양적인 의미를 넘어, '깊이'라는 속성이 인공지능에게 어떤 질적인 도약을 선사하는지 그 수학적·공학적 본질을 파헤쳐 보겠습니다.
1. 깊이의 미학: 왜 굳이 층을 쌓아야 하는가?
우리는 왜 퍼셉트론을 옆으로 넓게 펼치지 않고, 위로 높게 쌓아 올리는 'Deep'한 구조에 집착할까요? 그 해답은 계층적 특징 추출(Hierarchical Feature Extraction)이라는 딥러닝만의 독보적인 문제 해결 방식에 있습니다.
단순히 층을 많이 쌓는 것은 양적인 팽창이 아니라, 데이터를 바라보는 '관점의 수준'을 높이는 질적인 도약입니다.
1.1 복잡성의 분해: 추상화라는 이름의 계단
인간이 사물을 인식하는 과정은 지극히 찰나적이지만, 뇌 내부에서는 아주 정교한 단계별 연산이 일어납니다. 딥러닝은 바로 이 과정을 모사합니다. 여기서 중요한 점은 각 층(Layer)이 구조적으로 다른 것이 아니라, 학습을 통해 각 층이 담당하는 '추상화의 체급'이 달라진다는 사실입니다.
즉, 층을 쌓기만 하여도,
다음과 같이 인공신경망은 단계별로 입력받은 특징을 추출하고,
분석할 수 있게 됩니다.
[단계별 특징 추출의 메커니즘]
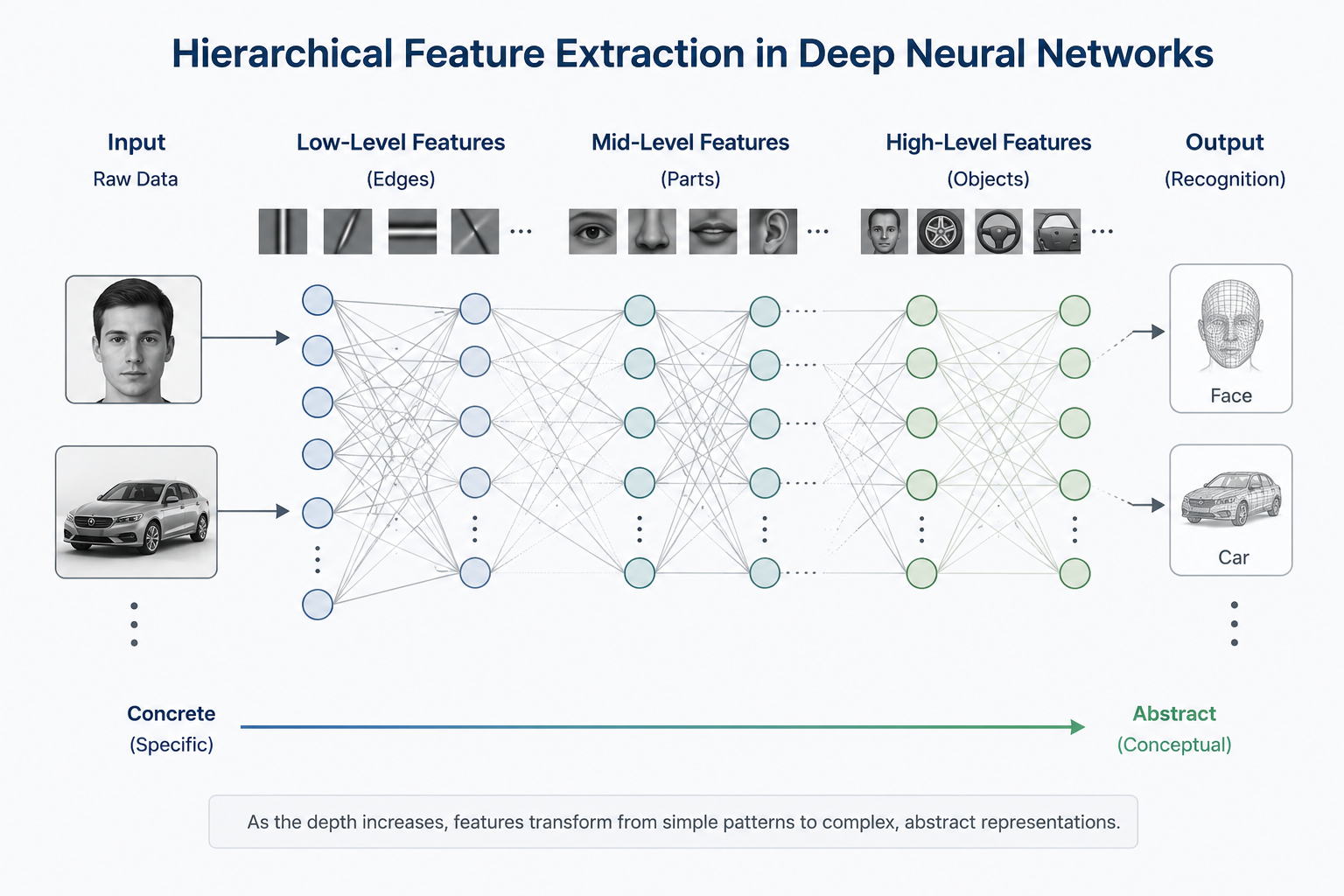
저수준 층 (Lower Layers) - "점과 선의 발견": 데이터가 처음 통과하는 층들입니다. 여기서는 이미지의 아주 작은 단위인 픽셀 간의 대비를 확인하여 '가로선', '세로선', '대각선' 혹은 '색상의 급격한 변화(Edge)' 같은 가장 기초적인 시각 요소들을 검출합니다.
중간 층 (Mid Layers) - "부품의 조립": 앞선 층에서 발견한 수많은 선을 조합합니다. 직선들이 모여 '바퀴의 둥근 곡선'이 되고, 수직·수평선이 만나 '자동차 창문의 사각형'이나 '헤드라이트의 원형' 같은 부분적인 기하학적 형태(Part)를 구성하기 시작합니다.
고수준 층 (Higher Layers) - "개념의 완성": 이제 부품들을 다시 조합하여 '차체', '문짝', '그릴' 등의 구체적인 형상을 만듭니다. 최종적으로 신경망은 이 모든 정보의 집합체를 통해 우리가 보는 것이 단순한 선들의 모임이 아니라 '자동차'라는 하나의 추상적인 개념임을 이해하게 됩니다.
이처럼 층을 쌓는다는 것은 복잡한 문제를 아주 단순한 문제들의 단계별 조합으로 변환하는 과정입니다. 깊은 신경망은 각 층을 거치며 데이터의 본질적인 특징을 단계적으로 추상화하며, 이것이 바로 딥러닝이 단순한 통계 모델을 넘어 '지능'의 영역으로 들어서는 지점입니다.
1.2 왜 '넓게'보다 '깊게'인가? (효율성의 경제학)
수학적으로는 은닉층이 단 하나뿐인 '얕고 넓은' 신경망도 이론상 모든 함수를 표현할 수 있습니다(보편적 근사 정리). 하지만 현실은 다릅니다.
지수적인 효율성: 얕은 신경망으로 복잡한 데이터를 표현하려면 필요한 노드의 수가 기하급수적으로 늘어납니다. (폭등한 램, 그래픽 카드 값을 버틸 수 없다..) 반면, 층을 깊게 쌓으면 이전 층에서 배운 지식을 다음 층이 '재사용'할 수 있기 때문에 훨씬 적은 수의 매개변수로도 압도적인 성능을 낼 수 있습니다.
공간의 분할: 층이 깊어질수록 신경망은 입력 공간을 더 많이 접고(Folding), 뒤틀 수 있습니다. 이는 복잡하게 꼬여있는 데이터들 사이를 아주 정교하게 가로지르는 '초평면'을 만들 수 있다는 뜻입니다.
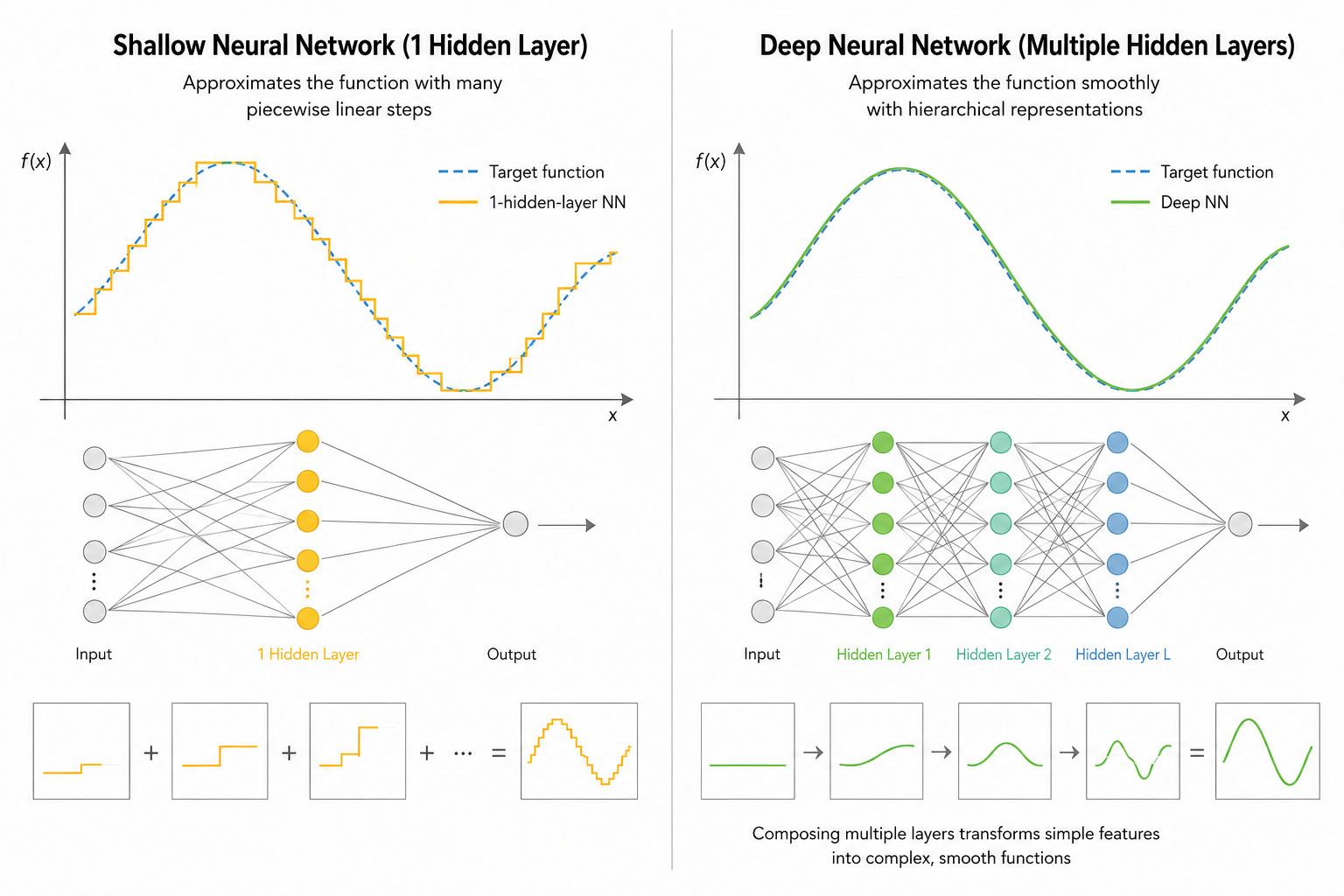
2. 수학적 증명: 보편적 근사 정리 (Universal Approximation Theorem)
"은닉층을 무한히 넓게 만들면 어떤 함수든 흉내 낼 수 있다면서요? 그럼 한 층만 넓게 쓰면 되는 거 아닌가요?"
딥러닝을 공부하다 보면 한 번쯤 마주하게 되는 날카로운 질문입니다. 실제로 1989년 시벤코(Cybenko) 등이 증명한 보편적 근사 정리에 따르면, 적절한 활성화 함수를 가진 하나의 은닉층만으로도 우리가 상상하는 거의 모든 연속 함수를 근사할 수 있습니다. 하지만 여기에는 실무적으로 불가능에 가까운 '효율성'이라는 거대한 함정이 숨어 있습니다.
2.1 깊이와 너비의 기회비용: 왜 '옆'이 아닌 '위'인가?
수학적으로 가능하다는 것이 공학적으로 효율적이라는 뜻은 아닙니다. 단층 구조로 복잡한 함수를 표현하려 할 때 발생하는 치명적인 한계는 다음과 같습니다.
지수적인 노드의 폭주: 단층 신경망이 깊은 신경망과 같은 수준의 복잡도를 표현하려면 노드의 수가 기하격수적(2^n)으로 늘어나야 합니다. 이는 메모리 폭발과 계산 불능 상태를 야기합니다.
매개변수의 효율성: 반면, 층을 깊게 쌓으면 아래 수식처럼 함수가 중첩(Composition)되면서 이전 층에서 계산된 결과를 재사용하게 됩니다.
f(x) = \sigma(W_L \sigma(W_{L-1} ... \sigma(W_1 x + b_1) ...) + b_L)
이 중첩 구조 덕분에 깊은 신경망은 훨씬 적은 수의 매개변수(Parameter)만으로도 동일하거나 훨씬 더 복잡한 함수를 우아하게 표현해냅니다. 얕은 층이 '조각조각 이어 붙여서' 정답을 흉내 낸다면, 깊은 층은 '논리적으로 추론하여' 정답을 찾아가는 셈입니다.
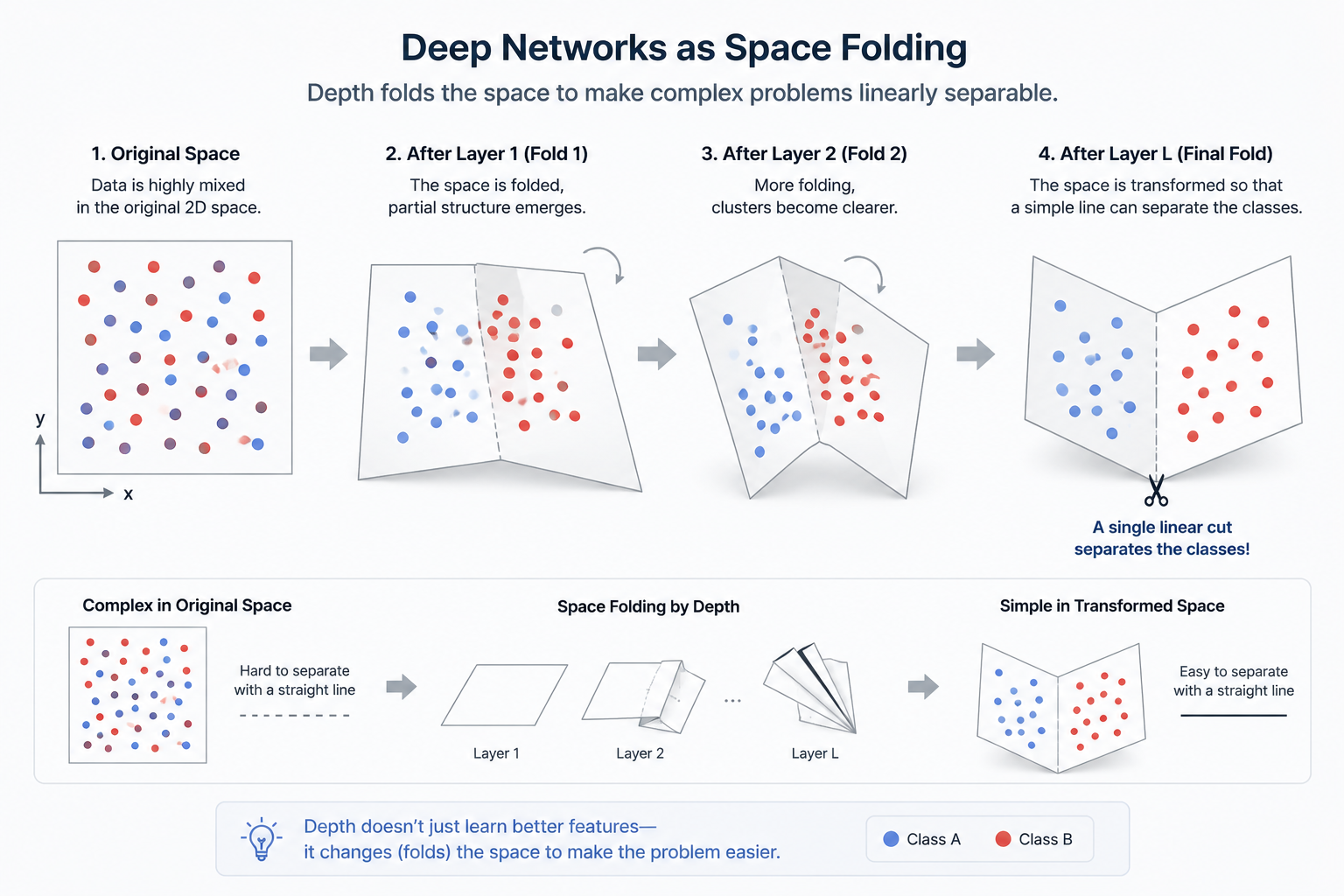
2.2 공간을 접는 마법 (Space Folding): 뇌의 입체적 망을 재현하다
2.2.1 차원을 빌려 문제를 해결하다
예를 들어, 평면(2차원) 위에 서로 엇갈려 있는 두 고리는 절대 끊지 않고는 분리할 수 없습니다. 하지만 이를 3차원 공간으로 가져가는 순간, 위쪽으로 살짝 들어 올리는 것만으로도 두 고리를 가볍게 분리할 수 있죠. 우리 뇌세포가 3차원으로 복잡하게 얽혀 사고를 빚어내듯, 딥러닝의 '깊이' 역시 고차원 공간을 물리적으로 비틀고 접는 효과를 냅니다.
신경망의 각 층(Layer)은 바로 이 '차원의 마법'을 수행합니다.
공간의 변형: 각 층을 지날 때마다 신경망은 입력 공간을 신축(Stretch)하고 압축(Compress)합니다.
공간의 접기(Folding): 활성화 함수를 통해 공간을 종이처럼 접어버립니다.
\text{Input Space} \xrightarrow{\text{Layer 1}} \text{Folded Space} \xrightarrow{\text{Layer 2}} \text{Twisted Space}
층이 깊어질수록 공간은 지수적으로 겹쳐지며, 마침내 복잡하게 꼬였던 데이터들은 아주 단순한 형태(Linear)로 정렬됩니다. 마지막 출력층에서는 단 하나의 직선만 그어도 복잡했던 문제가 우아하게 해결되는 것이죠.
3. 비선형 활성화 함수의 필연성: 층을 층답게 만드는 장치
우리가 이번 회차에서 다루어야 할 가장 중요한 통찰은 '활성화 함수가 없는 깊이는 그저 무의미한 숫자의 나열일 뿐'이라는 사실입니다. 단순히 층을 높게 쌓는다고 해서 지능이 탄생하는 것이 아닙니다. 층과 층 사이를 연결하는 이 작은 함수들이야말로 '선형'이라는 물리적 감옥을 탈출하게 해주는 유일한 열쇠입니다.
3.1 선형성의 저주: 1,000층을 쌓아도 결국 제자리인 이유
만약 활성화 함수 $\sigma$가 없는 순수한 선형 연산(y = Wx + b)만 반복한다면 어떤 일이 벌어질까요?
수학적으로 선형 변환의 합성은 결국 또 다른 선형 변환에 불과합니다. 예를 들어, 두 개의 층을 가진 신경망의 출력을 다음과 같이 가정해 봅시다.
y = W_2(W_1 x)
여기서 행렬의 곱셈 성질에 의해 W_2 W_1은 결국 하나의 새로운 행렬 W_{new}로 치환될 수 있습니다. 즉, 우리가 공학적 노력을 들여 층을 1,000개를 쌓더라도 비선형 활성화 함수가 없다면, 그 모델은 수학적으로 단 하나의 층을 가진 퍼셉트론과 완벽하게 동일한 능력을 가질 뿐입니다. 복잡한 XOR 문제를 풀기 위해 그토록 갈망했던 '곡선'의 경계선은 선형의 세계에서는 영원히 허락되지 않는 영역입니다.
3.2 비선형의 마법: 공간을 휘게 만드는 연금술
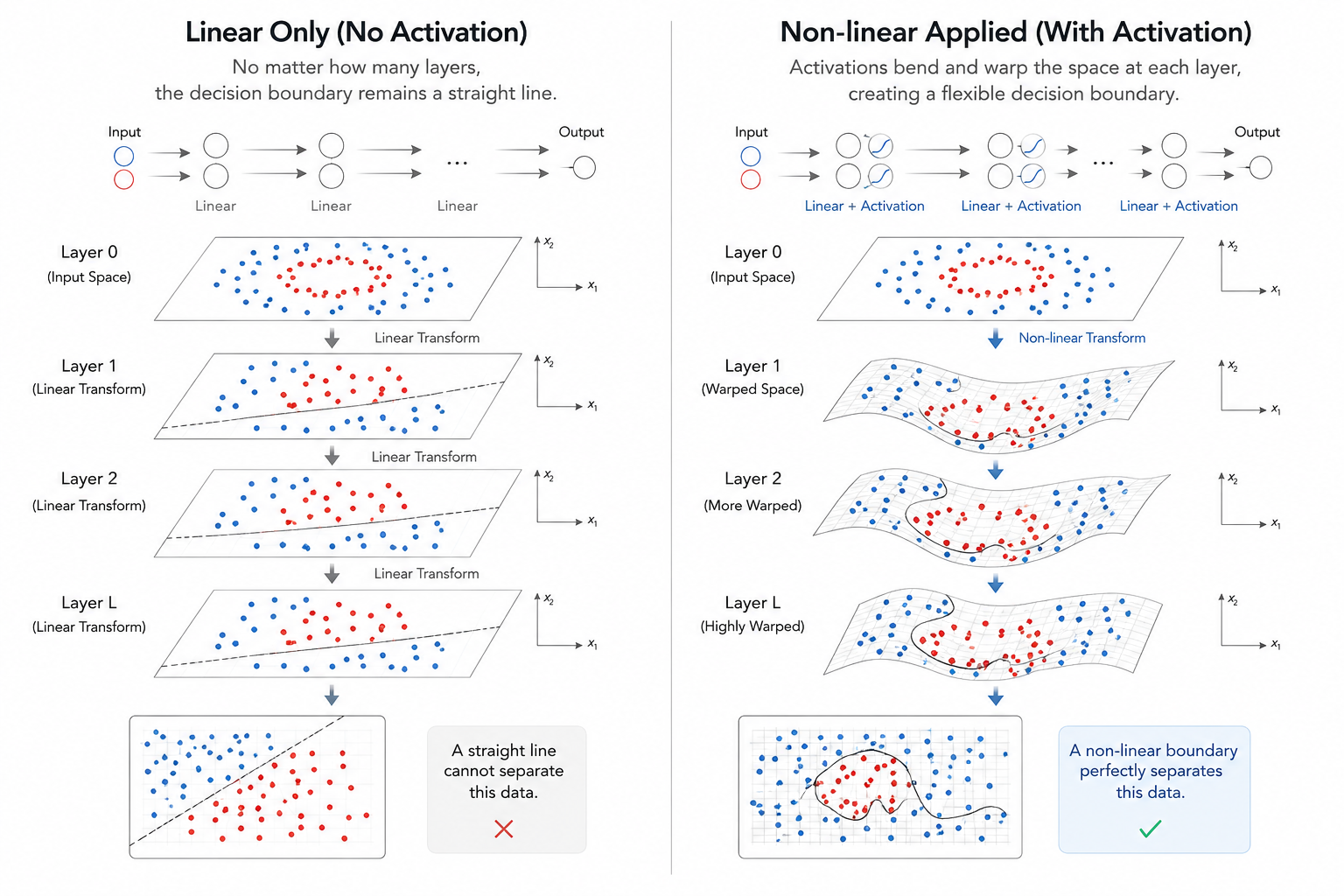
따라서 우리는 각 층의 연산 결과물에 의도적으로 비선형성(Non-linearity)을 주입합니다. 이 '비틀기'가 더해지는 순간, 신경망은 비로소 공간을 접고 휘게 만들며 데이터 사이를 유려하게 가로지르는 고도의 기하학적 연산을 수행하게 됩니다.
[시대의 흐름을 바꾼 대표적 활성화 함수들]
Sigmoid: f(x) = \frac{1}{1+e^{-x}} (구관이 명관)
어떤 입력값이라도 0과 1 사이의 값으로 매핑하여 부드러운 확률적 해석을 가능케 합니다.
초기 딥러닝의 부흥을 이끌었으나, 입력값이 매우 크거나 작아질수록 기울기(Gradient)가 0으로 수렴하여 학습이 멈춰버리는 '기울기 소실(Vanishing Gradient)'이라는 치명적인 약점을 안고 있습니다.
ReLU (Rectified Linear Unit): f(x) = \max(0, x) (MZ와 같은 세대교체)
0보다 작으면 신호를 완전히 차단하고, 0보다 크면 그대로 통과시키는 지극히 단순한 구조입니다.
하지만 이 단순함이 복잡한 미분 연산 속에서도 신호의 생명력을 유지시킵니다. 현대 딥러닝이 수백, 수천 층을 쌓아 올리면서도 오차의 에너지를 끝까지 전달할 수 있게 된 것은 순전히 이 함수 덕분이라 해도 과언이 아닙니다.
Tanh (Hyperbolic Tangent): f(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}}
출력의 중심을 0으로 맞추어(-1 부터 1) 다음 층으로 전달되는 신호의 편향을 줄여줍니다. 시그모이드보다 학습 속도가 빠르다는 장점이 있어 여전히 특정 구조에서 사랑받고 있습니다.
4. 딥(Deep)의 역설: 깊어질수록 찾아오는 시련
신경망에서 층을 깊게 쌓는 것이 무조건적인 성능 향상을 보장하지는 않습니다. 모델의 구조가 복잡해지고 깊어질수록, 수학적 신호가 제대로 전달되지 못하거나 데이터의 본질을 놓치는 심각한 부작용들이 발생하기 때문입니다.
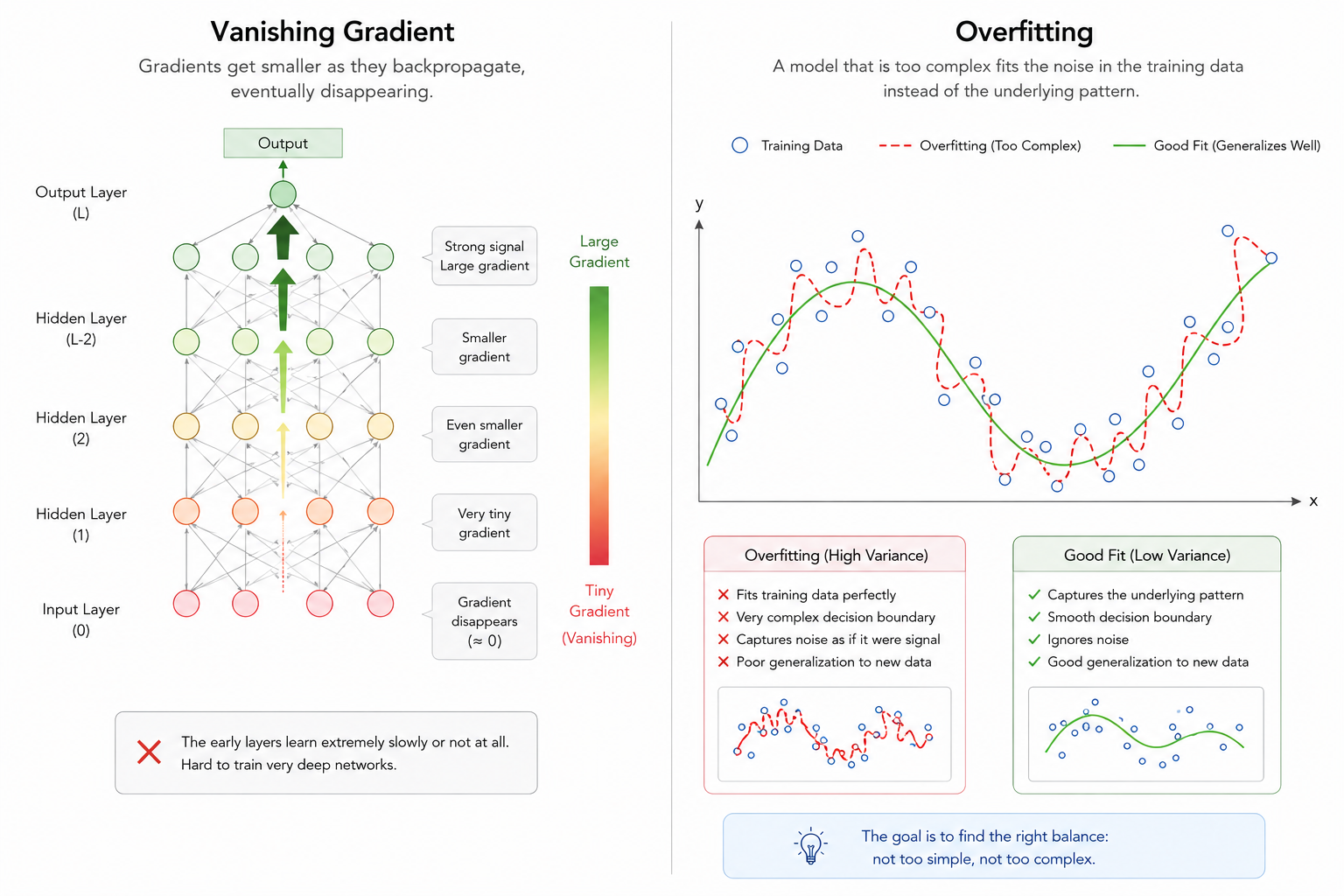
4.1 기울기 소실 (Vanishing Gradient): 심연에서 사라진 신호
역전파(Backpropagation) 알고리즘은 출력층에서 발생한 오차를 입력층 방향으로 거슬러 올라가며 가중치를 업데이트합니다. 이 과정에서 연쇄 법칙(Chain Rule)에 의해 각 층의 미분값이 계속해서 곱해지는데, 이것이 깊은 신경망의 치명적인 약점이 됩니다.
수학적 감쇄: 만약 특정 활성화 함수(예: Sigmoid)를 사용하여 각 층의 미분값이 1보다 작은 값(예: 0.25 이하)을 가진다면, 층이 깊어질수록 이 값들은 계속 곱해져 결국 0에 가까운 아주 작은 수치가 됩니다.
업데이트 중단: 결과적으로 입력층에 가까운 앞쪽 층들은 오차 신호를 거의 전달받지 못하게 됩니다. 가중치가 더 이상 업데이트되지 않으면서 학습이 사실상 멈춰버리는 현상, 이것이 바로 기울기 소실입니다.
4.2 과적합 (Overfitting): 데이터에 대한 과도한 집착
층이 깊어진다는 것은 모델이 학습할 수 있는 매개변수(Parameter)의 수가 많아지고 표현력이 극도로 높아진다는 의미입니다. 하지만 표현력이 너무 높으면 오히려 독이 됩니다.
잡음 학습: 깊은 모델은 훈련 데이터의 전반적인 특징뿐만 아니라, 그 데이터에만 존재하는 특수한 잡음(Noise)이나 사소한 패턴까지 모두 학습해 버립니다.
일반화 성능 저하: 이로 인해 훈련 데이터셋에 대해서는 매우 높은 정확도를 보이지만, 실제 서비스에 투입되어 본 적 없는 새로운 데이터를 만났을 때는 정확도가 급격히 떨어지는 일반화 실패 문제가 발생합니다.
5. 정리하며: 깊이는 곧 논리의 두께다
오늘 우리는 왜 인공지능이 'Deep'해져야만 했는지 그 필연성을 살펴보았습니다. 층을 쌓는 행위는 단순히 모델의 크기를 키우는 것이 아닙니다. 그것은 데이터를 다각도에서 해석하고, 추상적인 개념을 형성하며, 공간의 복잡함을 정복해 나가는 논리의 두께를 쌓는 작업입니다.
하지만 앞서 언급했듯, 무작정 깊게 쌓는다고 해서 정답이 나오지는 않습니다. 깊어질수록 신호는 약해지고, 모델은 오만해집니다. 다음 시간에는 이 '깊이의 저주'를 풀기 위해 등장한 천재적인 해결책들—활성화 함수의 혁명과 정규화 기법들—에 대해 논의해 보겠습니다. 인공지능이 어떻게 다시 한번 한계를 돌파했는지, 시즌 1의 최종장, 최적화(Optimization)에서 뵙겠습니다.
핵심 키워드 복습
계층적 특징 추출: 저수준의 특징을 조합해 고수준의 추상적 개념을 만드는 과정.
보편적 근사 정리: 깊은 층이 단층보다 훨씬 효율적으로 복잡한 함수를 표현할 수 있다는 수학적 근거.
기울기 소실 (Vanishing Gradient): 층이 깊어질수록 역전파되는 오차 신호가 소멸하는 현상.
비선형성: 신경망이 단순한 직선의 합을 넘어 복잡한 곡선과 평면을 그릴 수 있게 만드는 필수 장치.