Hello, this is MitornAve.
It’s been an incredible journey through Season 1. We started with the simple Perceptron, navigated the mathematical elegance of Backpropagation, and finally conquered the "Curse of Depth" using the engineering tools we discussed today. This foundation is the key to understanding the giant AI models of tomorrow—from CNNs that see images to Transformers that understand language.
Last time, we explored the "Magic of Abstraction" that depth grants to AI. But as the light grows brighter, the shadows deepen. As layers get deeper, we face the Vanishing Gradient problem, where signals disappear into the abyss, and Overfitting, where the model memorizes noise instead of patterns. Today, we reveal the optimization techniques that tore down these walls and ushered in the true era of Deep Learning.
1. The Evolution of Activation: The ReLU Revolution
The root cause of vanishing gradients lay in the Sigmoid function, the very tool that led early deep learning.
The Limit of Sigmoid: Sigmoid constrains values between 0 and 1, meaning its maximum derivative is only 0.25. Each layer cuts the signal by at least 1/4; after 10 layers, the signal shrinks to a millionth of its original strength, effectively vanishing.
The Arrival of ReLU: $f(x) = \max(0, x)$. This simple function became the savior of modern AI.
Lossless Transmission: In the positive region, the derivative is always 1. No matter how deep the layers, the error signal passes through like a "High-Pass" lane to the input layer.
The Beauty of Sparsity: By treating negative signals as 0, it forces the model to focus only on important features and drastically increases computation speed.
2. Weight Initialization: The Start Determines the Success
Weights ($W$) act as filters determining the strength of signals. If learning is the quest for the "best weights," then where we start determines how fast and successfully we finish.
2.1 The Trap of Zero: If all weights start at 0, every neuron performs the same calculation and receives the same error signal. Thousands of neurons would act as one, making deep layers useless. We must use Random Initialization to give each neuron its own "personality."
2.2 Balance of Variance: If weights are too small, signals vanish; if too large, they explode (causing NaN errors).
2.3 Xavier Initialization: Best for Sigmoid or Tanh. It sets variance based on the number of input ($n_{in}$) and output ($n_{out}$) nodes to keep signal variance consistent across layers.
2.4 He Initialization: The standard for ReLU. Since ReLU "kills" half the signals (negative ones), He Initialization sets the variance twice as high as Xavier to mathematically compensate.
3. Batch Normalization: Paving the Highway
When front layers learn, their output distribution changes. Back layers struggle to adapt to these shifting inputs—a phenomenon called Internal Covariate Shift. Batch Normalization (2015) solved this chaos.
Standardization: It forces data into a range with a mean of 0 and variance of 1.
The Highway Effect: It turns a bumpy, irregular dirt road into a smooth asphalt highway.
The Side Effects:
No more initialization stress: You don't have to be perfect with starting weights.
Quantum Jump in Speed: You can use much higher learning rates, finishing training 10x faster.
Natural Diet: It adds a bit of noise that acts like a "Natural Regularizer," preventing the model from obsessing over training data (overfitting).

4. Fighting Overfitting: Regularization

When a model becomes an "arrogant memorizer" of training data, we need to restrain it.
4.1 Dropout: We randomly "turn off" a percentage of neurons during training. This prevents "favoritism" toward specific neurons and forces the whole team to work together, creating a Robust model. It’s like a "Crossfit" workout that uses different muscles every day to balance the whole body.
4.2 L1/L2 Regularization: We give the model a "penalty" if its weights ($W$) get too large. Large weights mean the model is overly sensitive to specific data points. By forcing weights to stay small, we make the model's judgment lines smoother and more generalized.
5. The Evolution of Optimizers: Smart Pathfinding
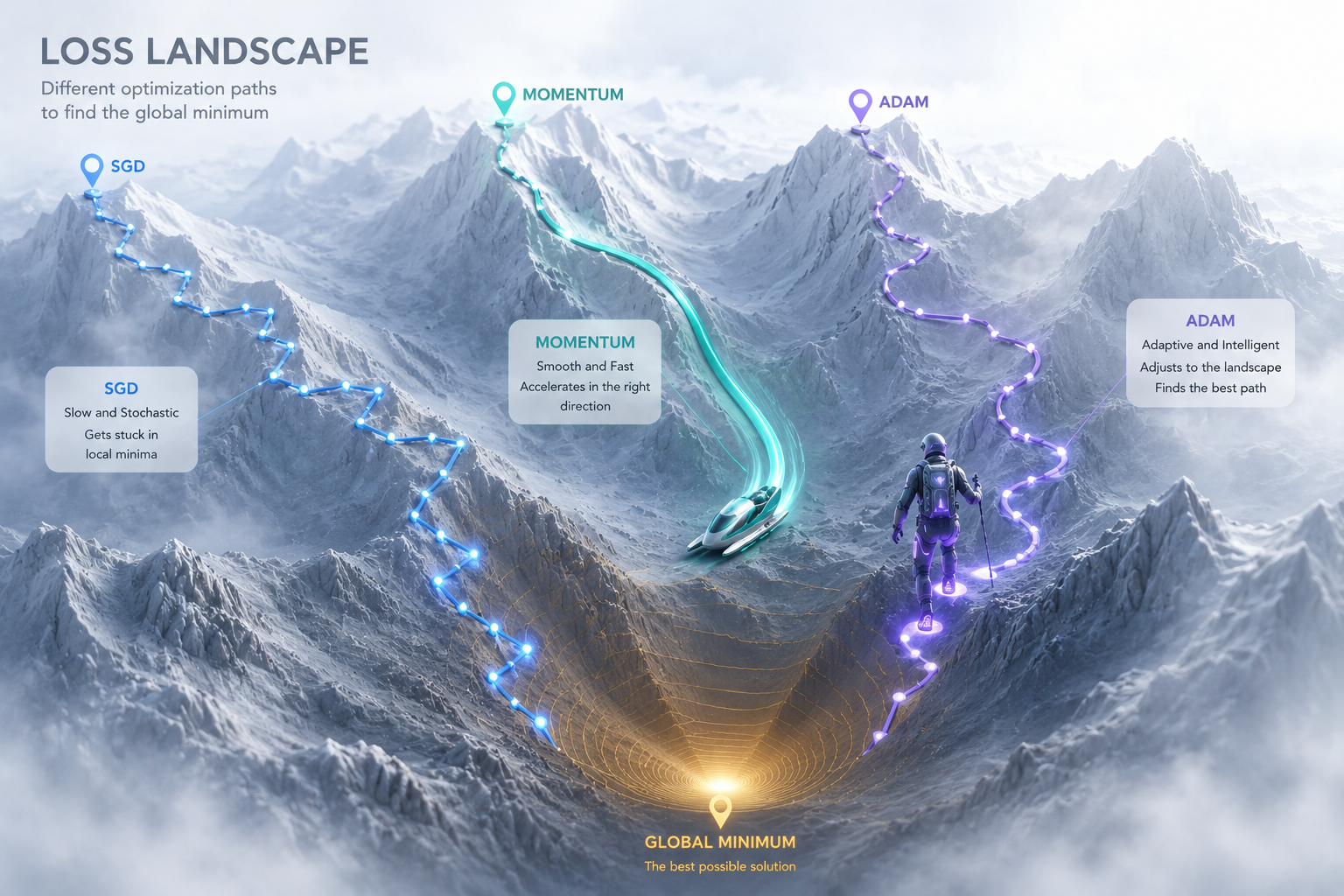
SGD is like walking down a mountain looking only at your feet. To move faster and more accurately, we use Optimizers.
5.1 Momentum: Uses inertia. Like a sled, it remembers previous speed to slide through flat spots or small pits (local minima).
5.2 AdaGrad & RMSProp: Uses adaptive stride. It walks carefully on steep slopes and takes big steps on flat ground, adjusting the learning rate for each variable.
5.3 Adam: The "Ultimate Combo." It combines the speed of Momentum with the precision of RMSProp. It is the industry standard for navigating the complex "Mountain of Error."
Key Takeaways
ReLU: The savior that solved Vanishing Gradients.
He Initialization: The optimal start for ReLU models.
Batch Norm: The highway that brings speed and stability.
Dropout: The strategy to keep AI from just "memorizing."